语言能力|中文语言能力评测基准「智源指数」问世:覆盖17种主流任务,19个代表性数据集,更全面、更均衡( 三 )
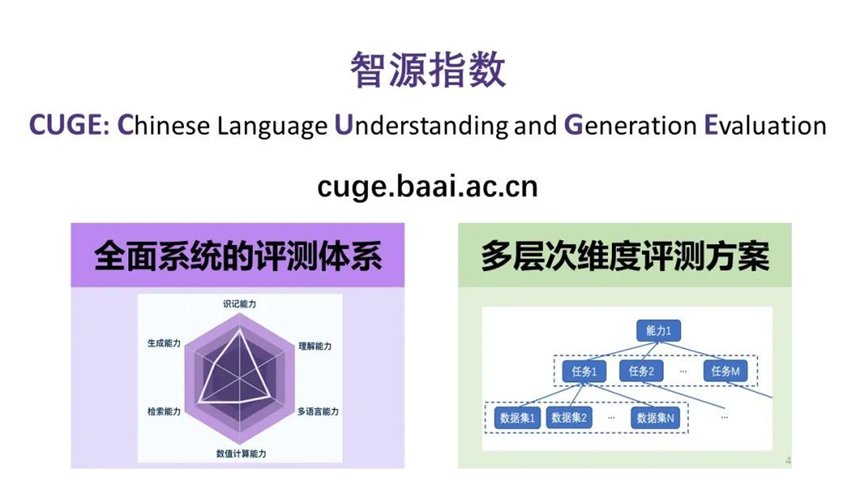
智源指数定位「中文语言」,覆盖自然语言理解和生成两大任务体系,按照「能力- 任务- 数据集」的层次结构筛选和组织高质量数据集,为机器语言能力提供更加全面系统和多层多维的评测标准。
文章插图
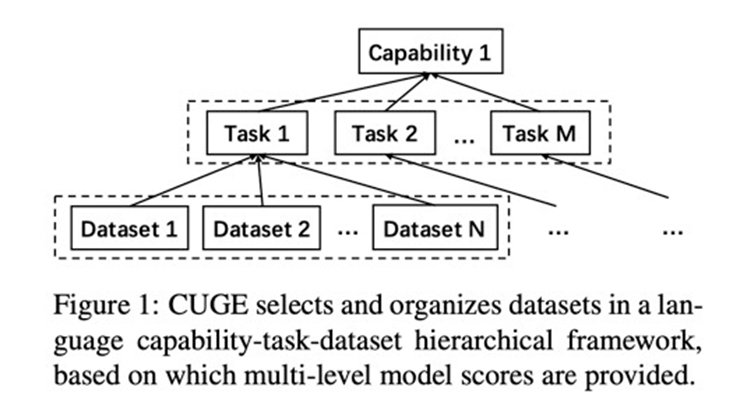
在评分策略上,传统评测基准通常直接将不同数据集上的得分平均得到总体得分,评测维度较为单一。而智源指数基于层次结构,提供了模型在数据集、任务、能力、总体不同层次维度的得分,并通过语言能力雷达图,直观地展示模型语言能力。
一般而言,将不同数据集上的不同指标直接平均,会受到不同数据集和指标不同特性的影响,最终得分也容易被少数得分变化幅度较大的数据集和指标主导,难以有效地全面衡量模型的语言能力进展。
文章插图
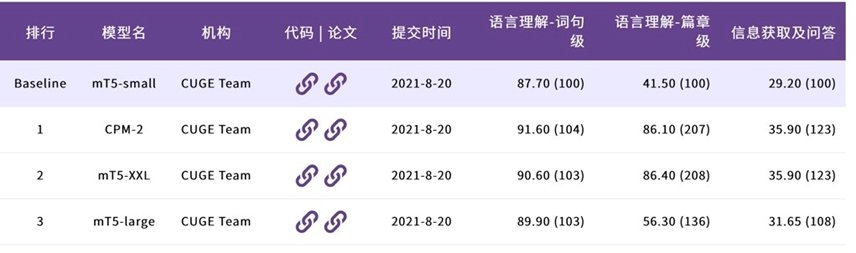
智源指数采用归一化方法计算得分,参考标准基线模型(mT5-small)的得分,计算参评模型的相对得分,最大程度消除不同数据集和指标特性影响。目前智源发布的大规模预训练模型CPM-2,以及mT5-small/large/XXL的评测结果已经在智源指数榜单上公布。
文章插图
以上可以看出,预训练模型在不同的语言能力表现的差异较大,通用的语言智能仍然有非常大的提升空间。
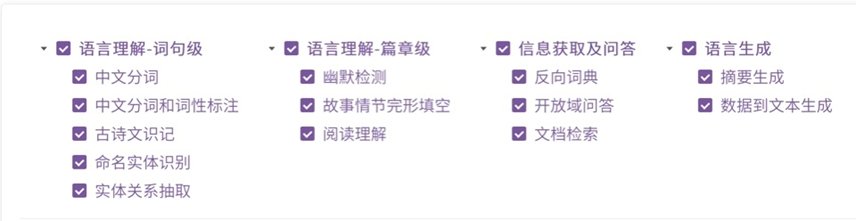
我们知道,基准任务和数据集支持着自然语言处理能力的开发和评估,是NLP工具的驱动力。智源指数覆盖了7 种重要语言能力,17 个主流自然语言处理任务,19个高质量数据集,分别为:
文章插图
- 语言理解-词句级:中文分词、中文分词和词性标注、古诗文识记、命名实体识别、实体关系抽取;
- 【 语言能力|中文语言能力评测基准「智源指数」问世:覆盖17种主流任务,19个代表性数据集,更全面、更均衡】语言理解-篇章级:幽默检测、故事情节完形填空、阅读理解;
- 信息获取及问答:反向词典、开放域问答、文档检索;
- 语言生成:摘要生成、数据到文本生成;
- 对话交互:知识驱动的对话生成;
- 多语言:机器翻译、跨语言摘要;
- 数学推理:数值计算。

文章插图
「智源指数」的一个重要的核心点是如何构建高质量、大跨度的标注语言资源库。在发布会现场,山西大学谭红叶教授和北京语言大学杨尔弘教授介绍了两个特色大规模数据集的标注规则和数据质量。
其中,面向可解释评测的高考于都理解数据集GCRC,汇集近10年高考阅读理解测试题包含5000多篇文本、8700多道选择题(约1.5万个选项)。标注信息涉及信息句子级支持事实、干扰项(不正确选项)错误原因、回答问题所需推理能力为三类,可从中间推理、模型能力两方面进行可解释评价。
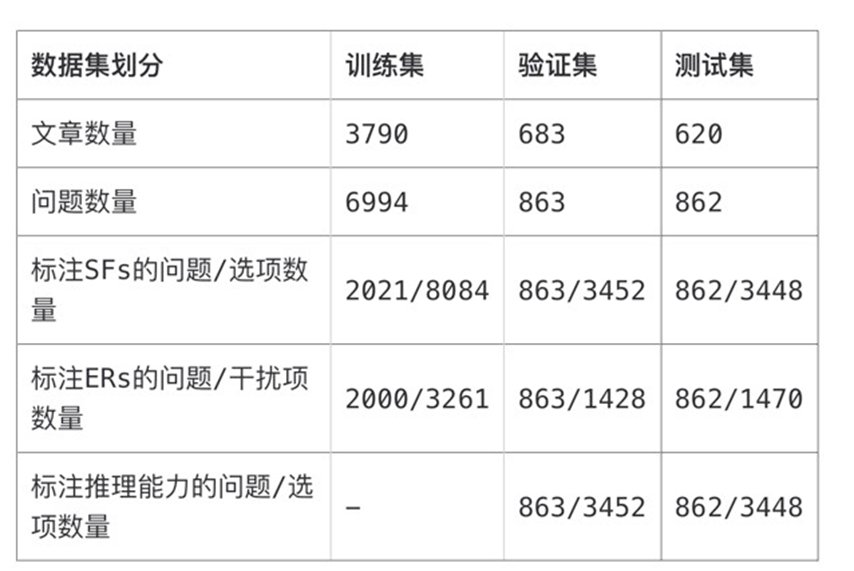
文章插图
二是面向汉语学习者文本多维标注数据集YACLC。该数据集由北京语言大学、清华大学、北京师范大学、云南师范大学、东北大学、上海财经大学等机构联合构建,其训练集规模高达8000条,每条数据包括原始句子及其多种纠偏标注与流利标注。验证集和测试集规模都为1000条,每条数据包括原始句子及其全部纠偏标注与流利标注。
- c语言|e观沧海丨算法焉能藏“算计”
- 自动驾驶|华为首秀自动驾驶,王兴:特斯拉遇到技术与忽悠能力相当的对手了
- 中文|爱数智慧CEO张晴晴:基于”情感“的人机交互,要从底层数据开始
- 罗永浩|有的人缺钱,和能力无关
- 晶圆|重构珠三角“芯”能力
- 广州联通|上传速率、覆盖能力大增!联通携手华为5G超级上行实现“跨站”规模首商用
- 中国联通|上传速率、覆盖能力大增!联通携手华为5G超级上行实现“跨站”规模首商用
- 高通骁龙|这一次它能将5G跑到极限:新骁龙8网络能力实测
- 折叠屏|折叠屏的抗反光能力有多强?测试显示全面超过日常家用平板
- 业务能力|亚信科技宣布收购艾瑞咨询 持续加码数字化运营及数智化转型