
文章图片

文章图片
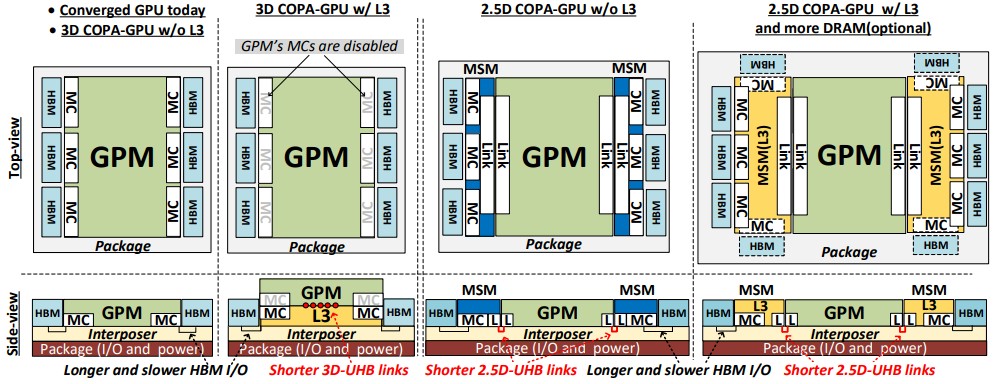
有两种类型的封装代表了计算的未来 , 并且都在某些领域有效:晶圆级集成和多芯片模块封装 。 虽然我们喜欢这样的想法 , 即您可以将包含在一个集群中的所有电路都放在一个硅晶片上 – 您可能能够将一两个机架或两个当今的异构 HPC 和 AI 节点设备缩减为一个闪亮的磁盘– 我们认为 , 在很多情况下 , 系统架构师更有可能需要比晶圆级集成所允许的更高的组件灵活性 。
顺便说一下 , 没有芯片设计师喜欢这两种选择中的任何一种 。 如果芯片设计师有他们的方式 。 Dennard 缩放仍然可以提高时钟速度 , 我们将拥有 50 GHz 芯片 , 而摩尔定律将允许晶体管成本每两年减少一半 , 因此芯片尺寸将保持不变 , 性能将保持不变上升和上升 。 但是丹纳德缩放在 2000 年代停止了 , 而摩尔定律 , 至少我们知道 , 使用助行器四处走动 。
因此 , 每家制造用于数据中心的计算引擎的公司都面临着这两种方法之间的选择 。 晶圆级集成迫使提前确定组件选择 , 除非它们包括可延展的 FPGA 电路(这也许不是一个坏主意) , 否则它们无法改变 。 并且它必须能够适应适合电路 SRAM 的工作负载 , 或者面临同样的问题 , 即从晶圆上取下电线以与慢得多的存储器通信 。 在某些时候 , 必须集成晶圆级计算机 , 并且您会遇到相同的互连问题 , 但由于晶圆本身的密度而变得更加复杂 。
因为多芯片模块封装 , 或 MCM , 我们经常说它是一种小芯片架构 , 已经存在了几十年——IBM 在 System/3081 大型机中构建了多芯片模块35 年前 , 其中有 133 个芯片 , 并将整个 IBM System/370 大型机的数据处理能力打包在一个模块中 , 而这与几十年前一样——我们认为这将是主流计算的前进方向 。 (也就是说 , 我们认为在大规模分布式互联网中让每个家庭由几个晶圆级服务器节点供暖是一个非常有趣的想法 , 显然每个快餐店也可以将它们用作烤架 。 )IBM、AMD、英特尔、和其他一直在数据中心提供计算引擎的人一直在构建 MCM CPU 二十年 , 我们可以看到这已经演变成一个更加优雅的小芯片架构 , 其中芯片的各个组件被打破并以有趣的方式组合 。 在许多设计中 , 核心复合体正在脱离内存和外围控制器 。
【GPU|NVIDIA RESEARCH 为多个多芯片 GPU 引擎设计了一个课程】随着其数据中心 GPU 面临代工合作伙伴台积电和三星的光罩限制 , 英伟达的研究人员一直在研究 MCM 封装以绘制从单片设计开始的路线也就不足为奇了 , 到目前为止 , 是其 GPU 计算引擎的标志 , 从“开普勒”到“安培”系列 , 其历史可追溯至 2008 年至今 。 该研究在一篇论文中得到了强调 , 该论文将由 ACM 于 3 月在其《架构和代码优化交易》期刊上发表 , 但于 2021 年 12 月在线发布 , 它指出了英伟达正在努力解决的一些问题 , 因为它将我们都希望在 3 月份的 GPU 技术大会上看到的“A100 Next”GPU 引擎(有时被称为“Hopper”GH100 , 但英伟达尚未证实这一点)以及将于 2024 年推出的“A100 Next Next”GPU 引擎 。
正如研究人员所表明的那样 , 问题不仅在于封装选项 , 还在于驱动 Nvidia 数据中心业务的非常不同的 HPC 模拟和建模以及 AI 推理和训练工作负载的计算和内存需求的差异 。
- GPU|天玑8000新机快了,相机的配置看上去挺不错,准备冲吗?
- 三星|三星手机Soc搭载AMD Radeon GPU曝光,运行频率超过苹果A15
- 算力|不靠显卡!NVIDIA在中国焕发第二春:自动驾驶芯片被车厂爆买
- gpu|登临科技完成新一轮战略融资,高通创投、光远资本等产业基金持续加持
- NVIDIA|800块钱买RTX 3090/RX 6900 XT?日本开卖显卡盲盒
- GPU|AI计算平台公司“登临科技”完成新一轮战略融资
- NVIDIA|1899原价买不到 RTX 3050显卡已涨到约2800元:溢价近50%
- 英伟达|NVIDIA晒《黑客帝国4》定制版3080 Ti:中国限量仅此一块
- iPhoneSE|NVIDIA新版RTX 3060 Ti曝光,连核心也变了
- gpu|国产 GPU 公司摩尔线程与同方达成合作