Jeff De2021谷歌年度 Jeff( 四 )
此外,GSPMD 描述了一种基于 XLA 编译器的自动并行化系统,该系统能够将大多数深度学习网络架构扩展到加速器的内存容量之外,并已应用于许多大型模型,例如 GShard-M4、LaMDA、BigSSL、ViT、MetNet -2 和 GLaM,在多个领域产生了最先进的成果。
文章插图
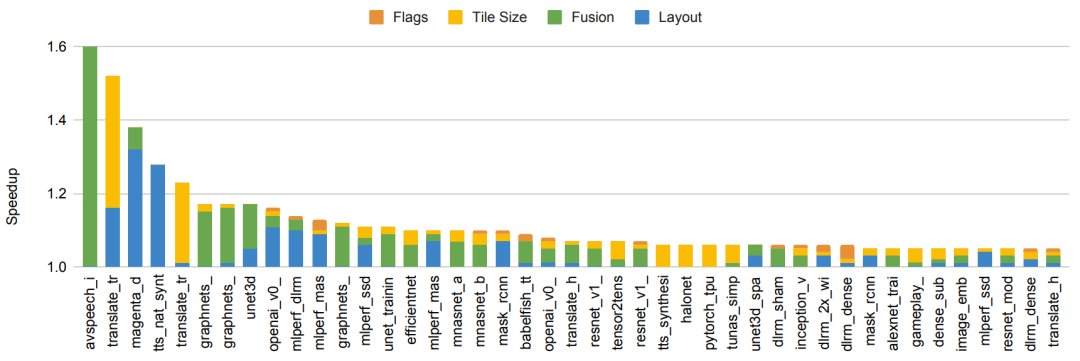
图注:通过在 150 个 ML 模型上使用基于 ML 的编译器自动调整实现端到端模型加速。图中包括实现 5% 或更多改进的模型。条形颜色代表优化不同模型组件的相对改进。
人类创造的更高效模型架构
模型架构的持续改进大大减少了为许多问题实现给定精度水平所需的计算量。
例如,谷歌在 2017 年开发的 Transformer 架构能够提高在多个 NLP 基准上的当前最佳水平,同时使用比其他各种常用方法少 10 到 100 倍的计算来实现这些结果,例如 LSTM 和其他循环架构。
同样,尽管使用的计算量比卷积神经网络少 4 到 10 倍,但视觉 Transformer 能够在许多不同的图像分类任务上显示出改善的最先进结果。
机器驱动的更高效模型架构的发现
神经架构搜索(NAS)可以自动发现对给定问题域更有效的新 ML 架构。NAS 的一个主要优点是它可以大大减少算法开发所需的工作量,因为 NAS 只需要对每个搜索空间和问题域组合进行单次检验。
此外,虽然执行 NAS 的初始工作在计算上可能很昂贵,但由此产生的模型可以大大减少下游研究和生产设置中的计算,从而大大降低总体资源需求。
例如,发现 Evolved Transformer 的单次搜索仅产生了 3.2 吨二氧化碳当量(远低于其他地方报告的 284 吨二氧化碳当量),但产生了一个比普通的 Transformer 模型效率高 15-20%的模型。
最近,谷歌利用 NAS 发现了一种更高效的架构,称为 Primer(也已开源),与普通的 Transformer 模型相比,它可以将训练成本降低 4 倍。通过这种方式,NAS 搜索的发现成本通常可以从使用发现的更有效的模型架构中收回,即使它们仅应用于少数下游任务(NAS 结果可被重复使用数千次)。
文章插图
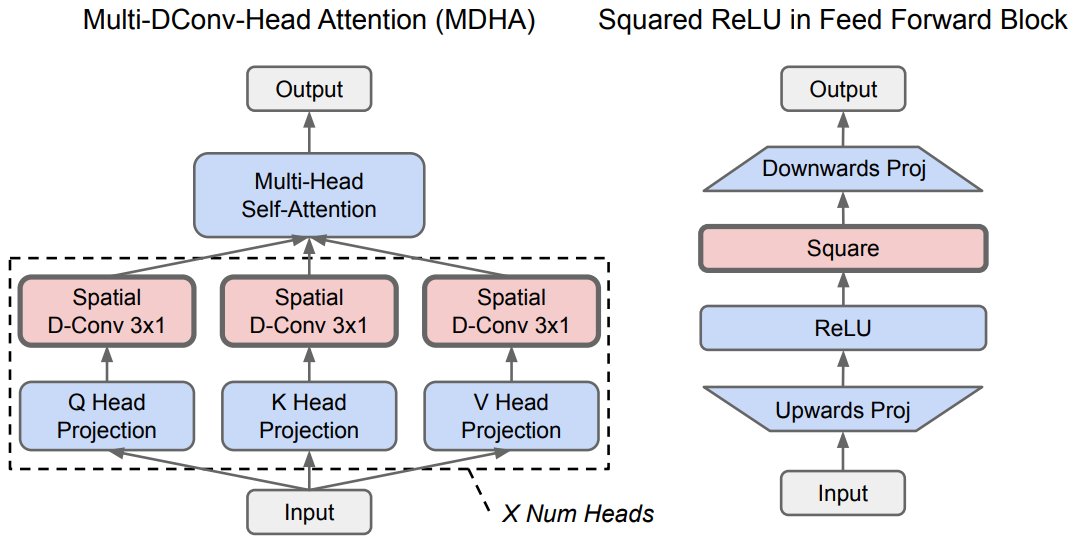
CoAtNet 模型架构是通过架构搜索发现的,结合了视觉 Transformer 和卷积网络来创建一个混合模型架构,其训练速度比视觉 Transformer 快 4 倍,并实现了新的 ImageNet 最先进结果。
文章插图
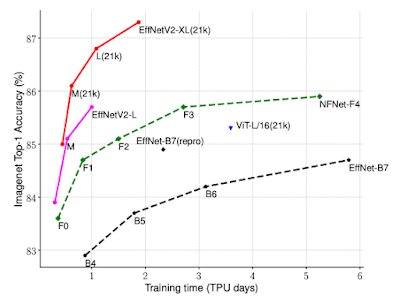
图注:EfficientNetV2 的训练效率比之前的 ImageNet 分类模型要好得多。
广泛使用搜索来帮助改进 ML 模型架构和算法,包括使用强化学习和进化技术,激发了其他研究人员将这种方法应用于不同领域。
除了模型架构之外,自动搜索还可用于寻找新的、更有效的强化学习算法,建立在早期的 AutoML-Zero 工作的基础上。
稀疏性的利用
稀疏性模型具有非常大的容量,但对于给定的数据(示例或 token ),只有模型的某些部分被激活,这是另一个可以大大提高效率的重要算法进步。
- Pixel|2800元的谷歌Pixel 5a成老外眼中最好的手机之一:可惜没人关注
- 谷歌Pixel|谷歌Pixel 6 Pro经常没信号:官方推送更新修复
- Java|假如让谷歌浏览器进入中国市场,国产浏览器会受到很大影响吗?
- Pixel|致敬OPPO Find N!谷歌折叠屏曝光:价格不到11000元
- Pixel|近6000块的谷歌Pixel 6 Pro被知名博主吐槽:体验太差 换回S21 Ultra
- 搜索引擎|华为自研搜索引擎上线,无任何广告,无视百度,对标谷歌
- 谷歌|Alphabet赋予其他子公司更大自主权,不效仿谷歌架构
- 英特尔|欧洲消费者:放弃使用谷歌软件而使用华为软件,几乎不可能发生
- 零售业|华为自研搜索引擎上线,无任何广告,无视百度,对标谷歌
- Google|为何谷歌地图能一家独大?收购多家公司,资金实力领先众多企业