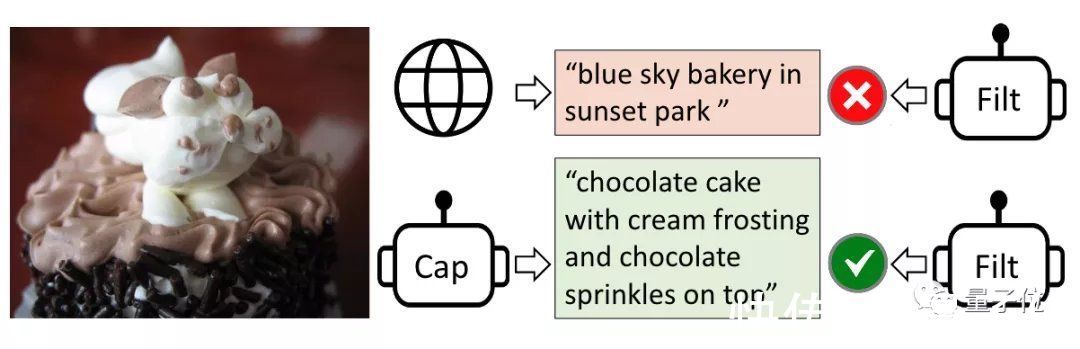
CapFilt中主要包含标注器 (captioner)和过滤器 (filter)两个部分。
其中,标注器用来生成描述图像的文本,过滤器将带有噪音的结果排除掉。
文章插图
比如下面的几个例子,就是过滤器将错误的答案驳回。

文章插图
研究表明,标注器列出的文本越多样化,最后的效果越好。
与此前取得SOTA的方法相比,BLIP在图像-文本检索任务上recall@1平均提升了2.7%;在看图生成文字上,CIDEr提升2.8%,视觉问答方面分数提升了1.6%。
通讯作者为清华校友此项研究的通讯作者为许主洪 (Steven C.H. Hoi)。

文章插图
他目前也任职于Salesforce亚洲研究院。此前为新加坡国立大学信息系统学院教授。
2002年,许主洪在清华大学计算机系获得学士学位。于2004年、2006年先后在香港大学计算机科学与工程系获得硕士、博士学位。
2019年当选IEEE Fellow。主要研究领域有计算机视觉、NLP、深度学习等。
第一作者为Junnan Li。

文章插图
他目前是Salesforce亚洲研究院高级研究科学家。
本科毕业于香港大学,博士毕业于新加坡国立大学。
研究领域很广泛,包括自我监督学习、半监督学习、弱监督学习、迁移学习、视觉-语言。
其余两位作者也均为华人,分别是Dongxu Li和Caiming Xiong。
论文地址:
https://arxiv.org/abs/2201.12086
试玩地址:
https://huggingface.co/spaces/akhaliq/BLIP
GitHub地址:
https://github.com/salesforce/BLIP
— 完 —
量子位 QbitAI · 头条号签约
- 复盘|复盘总结近期的一个人工智能物联网(AIoT)项目?
- 程序员|有的软件公司宁愿花15k去重招一个应届生,也不加薪5k留住公司老程序员
- Redmi K50电竞版发布会邀请函图赏,内含AMG赛车模型
- 亚马逊|原理简单,但不知道怎么用?一文看懂「同期群模型」
- 团购|社区团购“最惨烈”的一年,下一个倒下的会是它吗?
- ARM|CEO离职,ARM收购案彻底失败!英特尔却用64亿做出一个意外举动
- 骁龙8 Gen 1“翻车”?搭载该芯片手机上市一个月,降价700元!
- 如果你有一个天才孩子,该怎么教育?
- 钱包即将保不住!情人节想送一个“口红”给女神,可惜支付不起
- 浏览器|浏览器的复杂程度,可以和一个操作系统媲美