https|陈丹琦带着清华特奖学弟发布新成果:打破谷歌BERT提出的训练规律( 二 )
文章插图
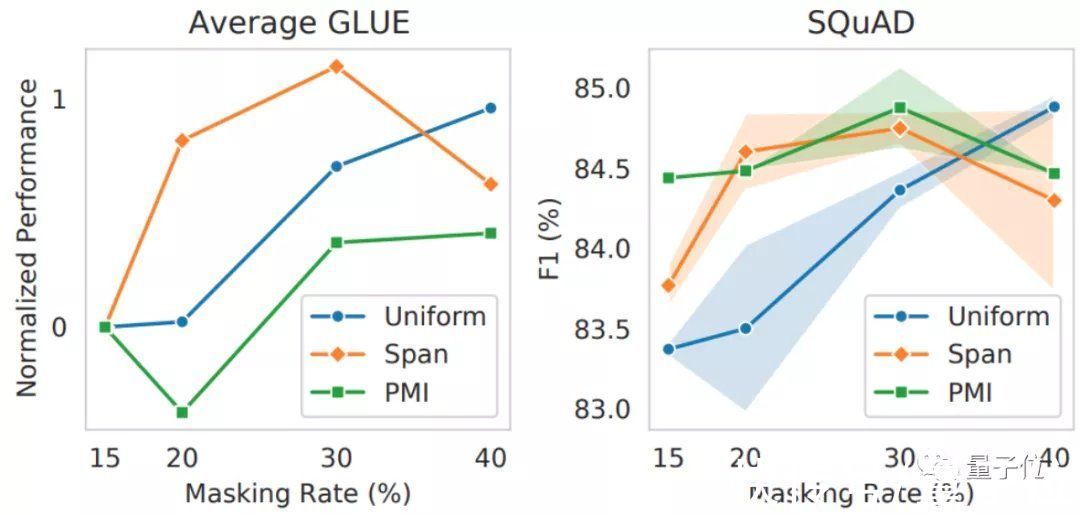
然而,在之前的很多NLP模型中,基本都直接采用了PMI-Masking或是Span Masking等更复杂的掩码来训练。
这也说明,NLP大模型的预训练效果不能一概而论,光是训练方法就值得进一步研究。
作者介绍论文的几名作者均来自陈丹琦团队。

文章插图
一作高天宇,目前是普林斯顿大学的二年级博士生,本科毕业于清华大学,曾经获得清华本科特等奖学金。
本科时,高天宇就在刘知远教授团队中搞科研了,期间一共发表了4篇顶会论文(两篇AAAI,两篇EMNLP)。

文章插图
共同一作Alexander Wettig,普林斯顿大学一年级博士生,本硕毕业于剑桥大学,对NLP的泛化能力方向感兴趣。

文章插图
钟泽轩(Zexuan Zhong),普林斯顿大学博士生,硕士毕业于伊利诺伊大学香槟分校,导师是谢涛;本科毕业于北京大学计算机系,曾在微软亚研院实习,导师是聂再清。
通过这一发现,不少NLP大模型说不定又能通过改进训练方法,取得更好的效果了。
论文地址:
https://gaotianyu.xyz/content/files/2022/02/should_you_mask_15-1.pdf
参考链接:
[1]https://twitter.com/gaotianyu1350/status/1493919318668713986【 https|陈丹琦带着清华特奖学弟发布新成果:打破谷歌BERT提出的训练规律】
[2]https://www.cs.princeton.edu/~awettig/
[3]https://www.cs.princeton.edu/~zzhong/
[4]https://gaotianyu.xyz/about/
— 完 —
量子位 QbitAI · 头条号签约
- https|9个压箱底的宝藏网站,个个都是黑科技的代表,请悄悄地收藏
- JK少女:带着那份甜蜜奔向你
- 带着Z 6Ⅱ和Z 28mm f/2.8捕捉街头精彩瞬间
- 显卡|我第一台电脑的显卡是,FX5200,它带着我踏上泰达希尔
- 原创|老师带着七台电脑来维修,结账时却只付一台钱,气得我扣下两台!
- 显示器|Doomscroll 永远带着超高 5: 16 便携式显示器
- 如果被鲸鱼吞下,身上恰好带着一把刀,可以划开肚子逃生吗?
- 带着“技术人员”跑了?挑选人才移民美国,拜登到底在怕啥?
- https|机器人首次独立手术!最快55分钟缝合肠道,“结果优于外科医生”
- https|Waymo起诉加州车管所,要求对无人车事故数据保密