半监督二维人体姿态估计中的模型坍塌问题研究(代码已开源)|ICCV 2021 | 一致性

文章插图
AI科技评论报道
文章插图
论文地址:https://arxiv.org/abs/2011.12498
目前半监督学习的方法中,结果最好的方法大多基于一致性训练(Consistency-based)[1][2]。也就是要求模型在一张图像的不同扰动(Perturbation)上产生一致的输出,从而去探索无标签图像中存在的特征。一致性损失如公式所示,
但当我们把这些方法应用到二维人体姿态估计时,我们发现大部分的一致性训练方法都遇到了模型坍塌的问题(Model Collapsing)—— 模型在有标注的图像上能够预测出正确的heatmap,但在无标注的图像上对每个像素的预测都是0。注意在这种情况下,虽然一致性损失是最小的,但模型在无标签数据上却没有学到任何有意义的信息。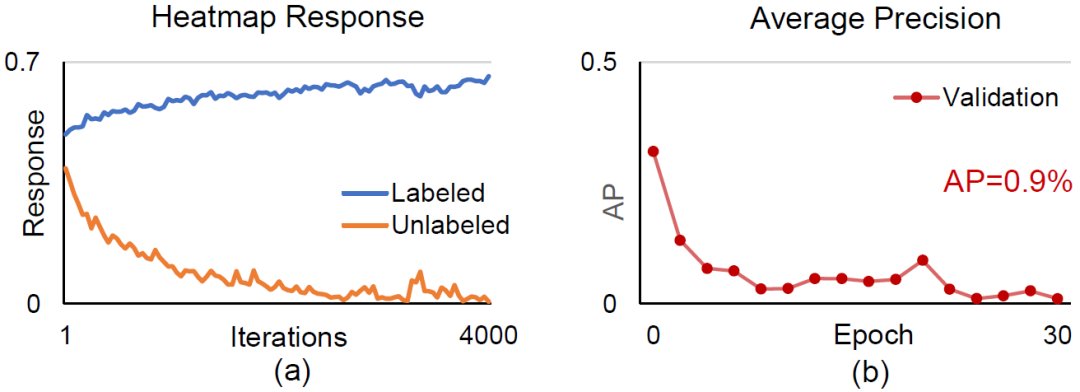
文章插图
- 《吉星高照》的谢怜杀青啦,半年的拍摄
- ios|时隔两个半月,微信 iOS 版迎来 8.0.17 正式版更新
- 中国半导体产业进入了技术驱动成长期 半导体及元件板块短线拉升|板块异动 | 拉升
- 二维码|微信Windows版3.5.0推送更新
- 芯片|半导体行业大赚!2021年第一季度19家企业宣布涨价
- 巴黎协定|纳微半导体成立全球首家电动车氮化镓功率芯片设计中心
- 半导体|晶闸管是什么? 四种常见晶闸管类型介绍
- 客服|2021年中国用户智能客服使用体验调研分析:近半数用户认为智能客服使用方便
- 时隔两个半月,微信 iOS 版迎来 8.0.17 正式版更新
- 张汝京再出发,事关芯片制造设备,国产半导体能否迎来转机?