样本|英伟达新研究:不用动捕,直接通过视频就能捕获3D人体动作
丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI不靠昂贵的动捕,直接通过视频也能提取3D人体模型然后进行生成训练: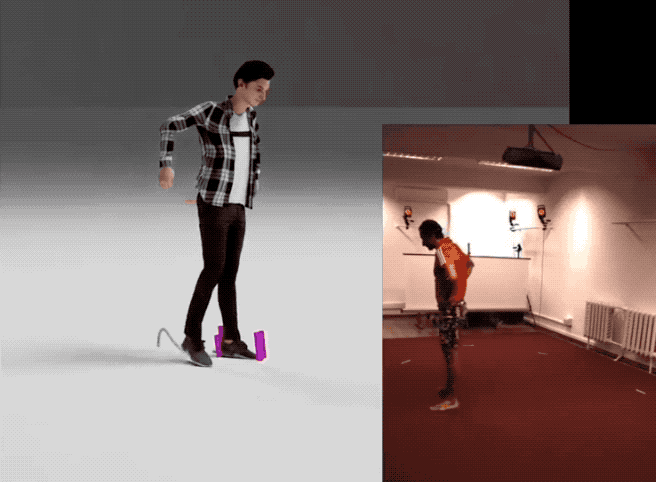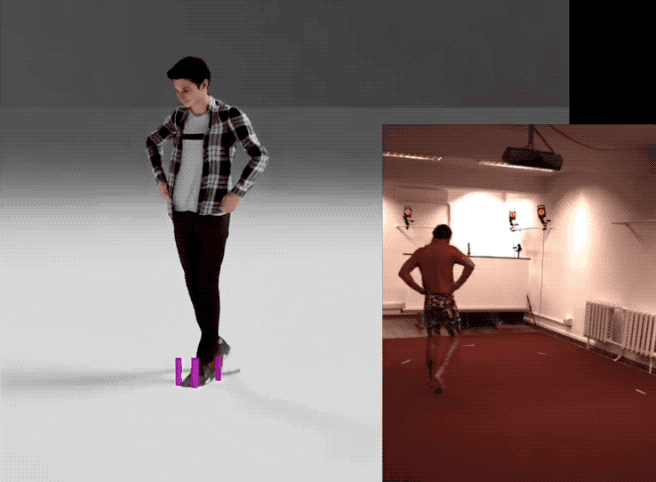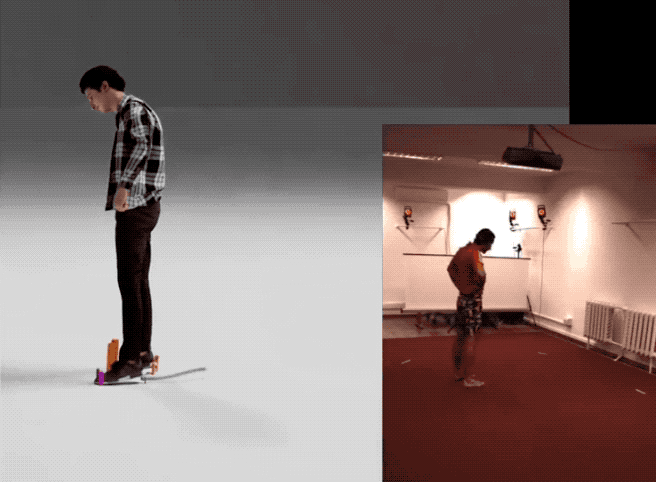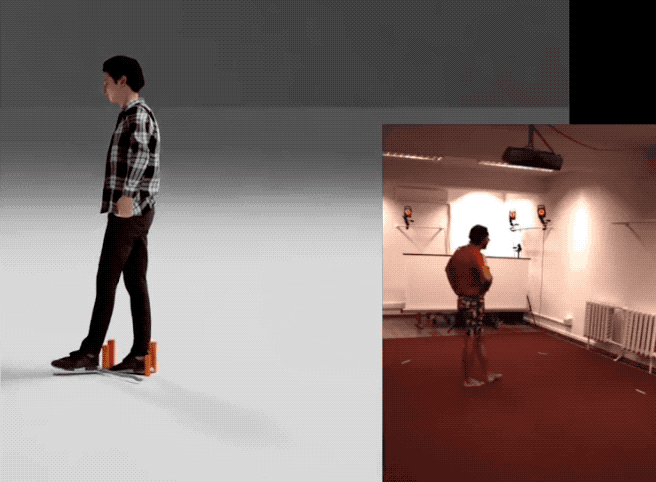
文章插图
文章插图
英伟达这项最新研究不仅省钱,效果也不错——
其合成的样本完全可以用在以往只在动捕数据集上训练的运动合成模型,且在合成动作的多样性上还能更胜一筹。
成果已被ICCV 2021接收。
文章插图
四个步骤从视频获得人体模型下图概述了英伟达提出的这个从视频中获得动作样本的框架。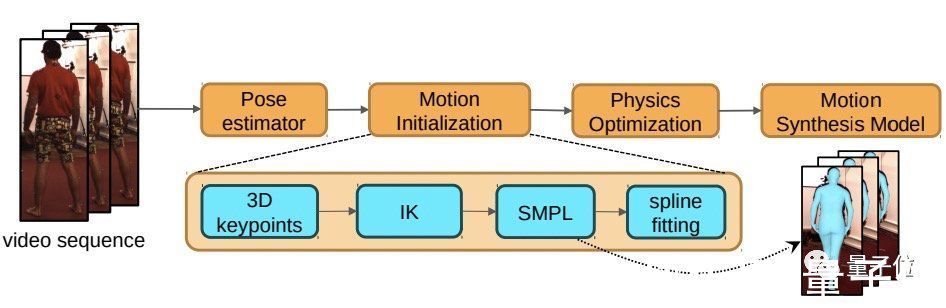
文章插图
【 样本|英伟达新研究:不用动捕,直接通过视频就能捕获3D人体动作】包含4步:
1、首先输入一个视频,使用单目姿势预估模型(pose estimator)生成由每帧图像组成的视频序列。
2、然后利用反向动力学,用每帧的3D关键点形成SMPL模型动作。
SMPL是一种参数化人体模型,也就是一种3D人体建模方法。
3、再使用他们提出的基于物理合理性的修正方法来优化上述动作;
4、 使用上述步骤处理所有视频,就可以使用获得的动作代替动捕来训练动作生成模型了。
概括起来就是用输入视频生成动作序列,然后建模成3D人体,再进行优化,最后就可以像使用标准动作捕捉数据集一样使用它们来训练你的动作生成模型。
下面是他们用该方法生成的一个样本合集:
文章插图
具体效果如何?研究人员对比了该方法与一些动捕模型,比如最新的PhysCap等。
PhysCap,一款基于AI算法的单目3D实时动捕方案。
结果发现,他们的方法在平均关节位置(MPJPE)的误差低于PhysCap。
文章插图
其中的基于物理的修正方法更是将样本的脚切线速度误差降低40%以上,高度误差降低80%。
文章插图
那用这些样本来训练生成模型的效果如何呢?
他们使用3个不同的训练数据集训练相同的DLow模型。
DLow(GT)是使用实际动捕数据进行训练的人体运动模型。
DLow(PE-dyn)是他们提出的方法,使用物理校正后的姿势训练。
DLow(PE-kin)也是他们的方法,没有优化过动作。
结果是DLow(PE-dyn)模型的多样性最好,超越了动捕数据集下的训练。
但在最终位移误差(FDE)和平均位移误差(ADE)上略逊一筹。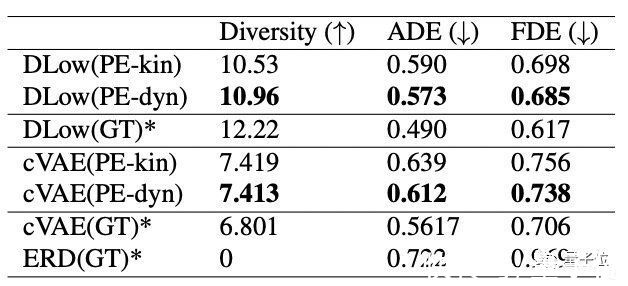
文章插图
最后,作者表示,希望这个方法继续改进成熟以后,能够非常强大地利用身边的在线视频资源为大规模、逼真和多样的运动合成铺平道路。
作者信息Xie Kevin,多伦多大学计算机专业硕士在读,也是英伟达AI Lab的实习生。
文章插图
王亭午,多伦多大学机器学习小组博士生,清华本科毕业,研究兴趣为强化学习和机器人技术,重点集中在迁移学习、模仿学习。
文章插图
Umar Iqbal,英伟达高级研究科学家,德国波恩大学计算机博士毕业。
文章插图
后面还有其他3位来自多伦多大学和英伟达的作者,就不一一介绍了。
论文地址:
https://arxiv.org/abs/2109.09913
- 百度|传英伟达加大GeForce RTX 3050供应力度,大量供货将在春节后到来
- 400亿芯片交易接近尾声,英伟达、ARM表明态度,禁止收购后
- 测试|解码自动驾驶商业化进阶的亦庄样本
- 恶意软件|报告称 2021 年 Linux 的恶意软件样本数量增加了 35%
- 军工|中国版“英伟达”诞生,核心技术完全自研,国产替代即将崛起
- 英伟达 RTX 3090 Ti 经销商定价曝光,约 2.2 万元起
- 英伟达|被称“中国版英伟达”,核心技术100%自研,年收入大涨超65%
- 英伟达发布12G显存版3080!AI超级分辨率:1080p帧数、4K画质
- 英伟达|NVIDIA晒《黑客帝国4》定制版3080 Ti:中国限量仅此一块
- 飞利浦·斯塔克|原价买显卡时代即将来临!英伟达:今年火力全开加大显卡产能