这就是华为速度:2.69秒完成BERT训练!新发CANN 5.0背后技术公开
金磊 萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
快,着实有点快。
现在,经典模型BERT只需2.69秒、ResNet只需16秒。
啪的一下,就能完成训练!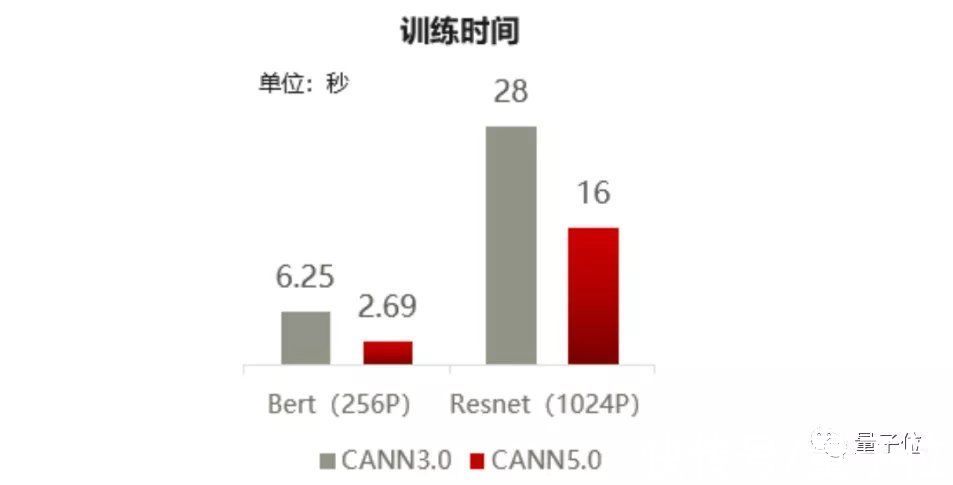
文章插图
这是华为全联接2021上,针对异构计算架构CANN 5.0放出的最新性能“预热”:
- 4K老电影AI修复,原本需要几天时间,现在几小时就能完成;
- 针对不同模型进行智能优化,300+模型都能获得30%性能收益;
- 支持超大参数模型、超大图片计算,几乎无需手动修改原代码……
为的就是尽可能提升AI模型的计算效率,减少在训练和推理上占用的时间。
它的存在,能让开发者在使用AI模型时,最大程度地发挥硬件的性能。
异构计算架构究竟为什么重要,昇腾CANN 5.0又究竟有哪些特性和优势?
我们对华为昇腾计算业务副总裁金颖进行了采访,从CANN 5.0的功能解读中一探究竟。

文章插图
为什么需要AI异构计算架构?首先来看看,AI异构计算架构到底是什么。
通常做AI模型分两步,先选用一种框架来搭建AI模型,像常见的Caffe、Tensorflow、PyTorch、MindSpore等;再选用合适的硬件(CPU、GPU等)来训练AI模型。
BUT,在AI训练框架和硬件之间,其实还有一层不可或缺的“中间架构”,用来优化AI模型在处理器上的运行性能,这就是AI异构计算架构。
【 这就是华为速度:2.69秒完成BERT训练!新发CANN 5.0背后技术公开】区别于同构计算(同类硬件分布式计算,像多核CPU),异构计算指将任务高效合理地分配给不同的硬件,例如GPU做浮点运算、NPU做神经网络运算、FPGA做定制化编程计算……

文章插图
面对各种AI任务,AI异构计算架构会充当“引路员”,针对硬件特点进行分工,用“组合拳”加速训练/推理速度,最大限度地发挥异构计算的优势。
如果不重视它,各类硬件在处理AI任务时,就可能出现“长跑选手被迫举重”的情况,硬件算力和效率不仅达不到最优,甚至可能比只用CPU/GPU更慢。
目前已有越来越多的企业和机构,注意到异构计算架构的重要性,开始着手布局相关技术,不少也会开放给开发者使用。
但开发者在使用这些异构计算架构时,会逐渐发现一个问题:
不少AI异构计算架构,基本只针对一种或几种特定场景来设计,如安防、客服等AI应用较成熟的场景;针对其他场景设计的AI模型,异构计算架构的性能会有所下降。
就像安防公司会针对安防类AI模型进行优化一样,这类异构计算架构往往不具有平台通用性。
这使得开发者在训练不同的AI模型时,需要在搭载不同异构计算架构的各类处理器之间“反复横跳”,找到训练效率最高的方法。
期间不仅要学习各类算子库、张量编译器、调优引擎的特性,还只能选用特定的训练框架,非常复杂。
相比之下,华为从2018年AI战略制定之初,就选择了一条不同的路线。
华为昇腾计算业务副总裁金颖在采访中表示:
我们认为,AI模型会由单一的、场景化的模式,逐渐走向通用化,而昇腾系列,就是针对全场景设计的解决方案。
其中,昇腾CANN作为平台级的异构计算架构,已经经过了3年多的优化,迭代了4个大版本。
现在,最新“预热”的CANN 5.0版本,在各种不同场景的模型和任务上,都表现出了不错的效果。
- 加盟行业|原来加盟行业是这么玩的!
- 华为|别不信!魅族如今处境,雷军早有预料,小米也早已体验
- 小米科技|预算只有两三千买这三款,颜值性能卓越,没有超高预算的用户看看
- 苹果|苹果最巅峰产品就是8,之后的产品,多少都有出现问题
- 魅族|对不起!魅族,这次确实令人失望了
- 华为|问界M5风光无限,赛力斯SF5暗自神伤,华为或许低估了造车这事?
- 华为鸿蒙系统|华为偷偷上架新机,鸿蒙系统+5000mAh大电池,仅售1399元
- 东南亚|MIUI13深度使用报告,这还是我认识的MIUI吗?网友评价很真实
- 苹果|马化腾称,腾讯只是一家普通公司,这是谦虚说法还是有所顾虑?
- 5G|关于5G,华为赢了