深度学习|通过短文本生成图像
文章图片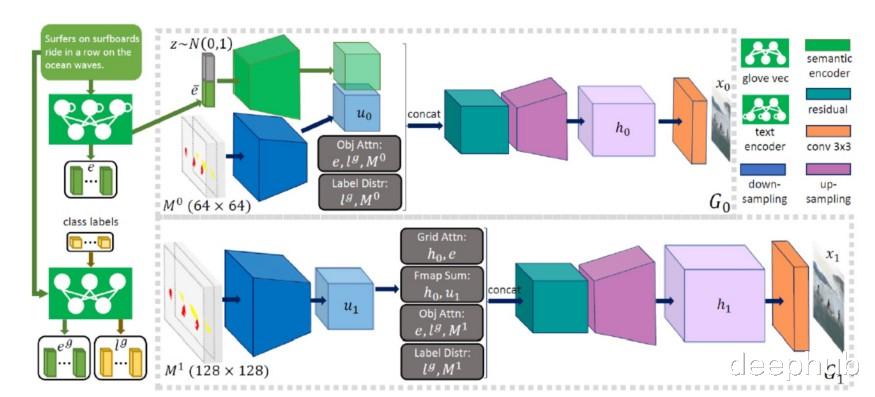
文章图片
【深度学习|通过短文本生成图像】人类可以在图像中构建知识 。每次我们看到一个想法或经验时 , 大脑都会立即对其进行视觉表示 。同样 , 我们的大脑也在不断地在声音或纹理等感官信号与其视觉表现之间切换上下文 。我们在视觉表示中思考的能力还没有完全扩展到人工智能 (AI) 算法 。 大多数 AI 模型都高度专业化于一种数据表示形式 , 例如图像、文本或声音 。而我们研究的最终目的是将开始看到可以在不同数据格式之间有效转换以优化知识创造的人工智能形式 。最近来自微软的 AI 研究人员发表了一篇论文 , 提出了一种基于短文本生成图像的方法 。
我们从声音或文字描述中产生视觉表征的能力是人类认知的神奇元素之一 。 如果你被要求画一幅篮球比赛的图像 , 你可能会从三到四名球员的轮廓开始 。 即使没有直接指定 , 您也可以添加一些细节 , 如乌鸦、裁判或处于特定位置的球员 。 所有这些细节都丰富了基本的文本描述 , 以实现我们对篮球比赛的视觉版本 。 如果人工智能模型也能做到这一点 , 那不是很好吗?文本到图像(Text-to-Image TTI)是深度学习的新兴学科之一 , 专注于从基本文本表示生成图像 。 虽然TTI领域还处于非常早期的阶段 , 但我们已经看到了一些切实的进展 , 一些模型已经在非常具体的场景中被证明是熟练的 。 然而 , 这些都是TTI模型中仍然需要解决的非常具体的挑战 。
从文本生成图像:挑战和注意事项有几个相关的挑战传统上阻碍了TTI模型的发展 , 但它们中的大多数可以归类为以下类别之一?
1)挑战:TTI模型高度依赖文本和可视化分析技术 , 尽管近年来它们取得了很大进展 , 但要实现主流方法 , 仍有很多工作要做 。 从这个角度来看 , TTI模型的功能通常会受到底层文本分析和图像生成模型的具体限制 。
2)概念-对象关系:TTI模型中难以解决的一个问题是从文本描述中提取的概念与其对应的可视对象之间的关系 。 实际上 , 可以有一个不定式数量的对象匹配一个特定的文本描述 。 确定概念和对象之间的正确匹配仍然是TTI模型的关键挑战 。
3)物物关系:任何图像都是以视觉的形式表达物体之间的关系 。 为了反映给定的叙述 , TTI模型不仅要生成正确的对象 , 还要生成它们之间的关系 。 在文本到图像的生成技术中 , 生成包含多个具有语义意义的对象的更复杂的场景仍然是一个重大的挑战 。
Object-Driven Attentive GAN为了解决TTI模型的一些传统挑战 , 微软研究院依赖于日益流行的生成对抗网络(gan)技术 。 gan通常由两种机器学习模型组成——一个生成器从文本描述生成图像 , 另一个判别器使用文本描述判断生成图像的真实性 。 生成器试图让假照片通过鉴别器;另一方面 , 辨别器不希望被愚弄 。 通过共同努力 , 鉴别器将生成器推向完美 。 微软在传统的GAN模型上进行了创新 , 引入了自下而上的注意力机制 。 Obj-GAN模型开发了一个对象驱动的注意力生成器和一个面向对象的识别器 , 使gan能够合成复杂场景的高质量图像 。
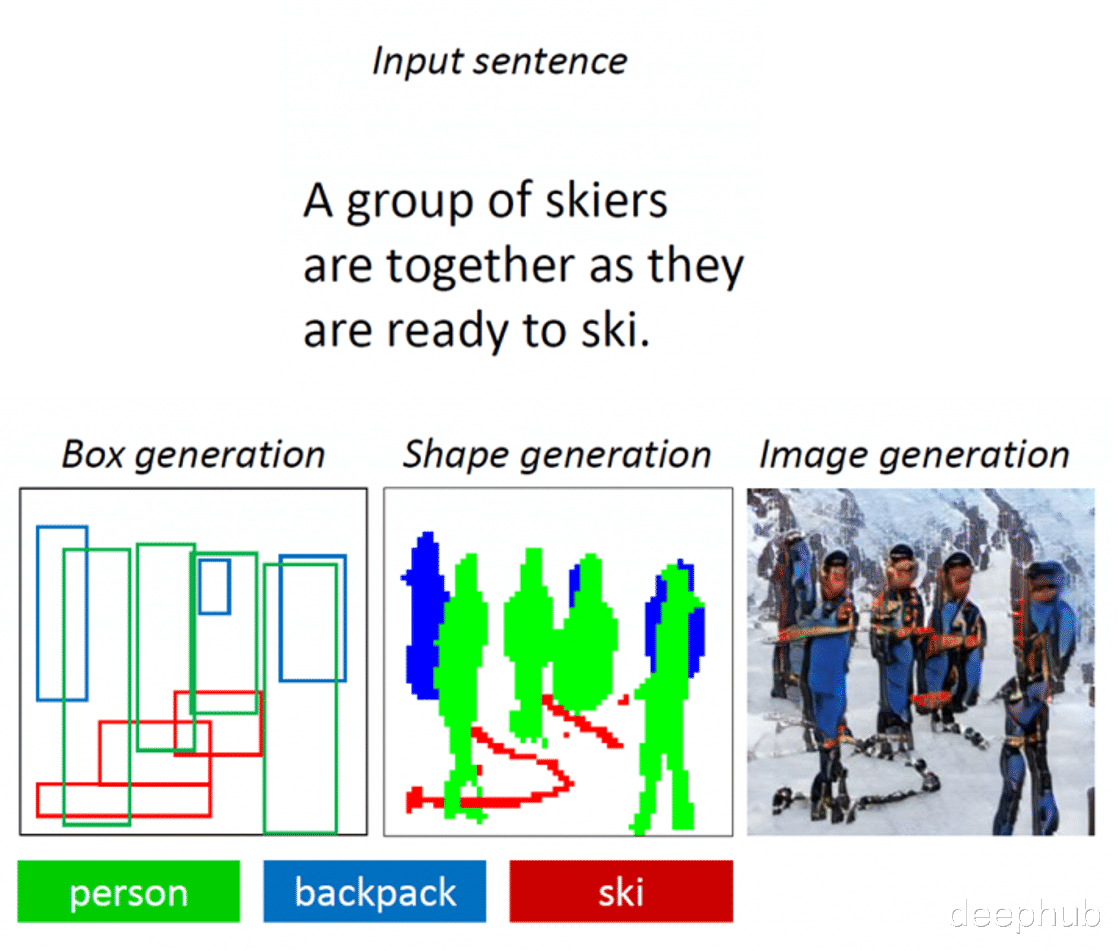
Obj-GAN的核心架构通过两个步骤进行TTI合成:
1)生成语义布局:这个阶段包括生成类标签、包围框、突出物体的形状等元素 。 这个功能由两个主要组件完成:Box Generator和Shape Generator 。
2)生成最终图像:这个功能是由一个多级图像生成器和一个鉴别器完成的 。
- 知乎|电商达人迎来补税大潮,知乎带货第一人,被通知补税34万!
- m都是大片!微软 Skype 支持将必应 Bing 图片设为通话虚拟背景
- 高通骁龙|首批骁龙8旗舰谁更值得买?懂行人带你客观分析每台新机亮点
- 东南亚|MIUI13深度使用报告,这还是我认识的MIUI吗?网友评价很真实
- 苹果|马化腾称,腾讯只是一家普通公司,这是谦虚说法还是有所顾虑?
- 卢照邻 关山月
- 打脸!华为在美国,用专利把英特尔、苹果、微软、高通打败了
- 将理论注入深度学习,对过渡金属表面进行可解释的化学反应性预测
- iqoo neo|开始退场!红米K40最强对手清仓:高通870+独显,直降300历史最低
- 高通骁龙|发布一个月仍供不应求,144Hz+12G+256G,开售几乎秒售完