ssd|中国如何赢得新一轮超算竞赛?关键在向数据密集型超算转变( 三 )
自动驾驶行业还有一个难点是不同环节要求的数据协议不同。
数据导入时需要的是S3/NFS格式,数据预处理需要HDFS格式,AI训练又需要NFS格式,后面还有仿真、模型验证….
结果是,数据转换格式和来回拷贝的时间比处理分析时间还多一倍,这要求未来的数据密集型超算还要解决数据协议互通的问题。‘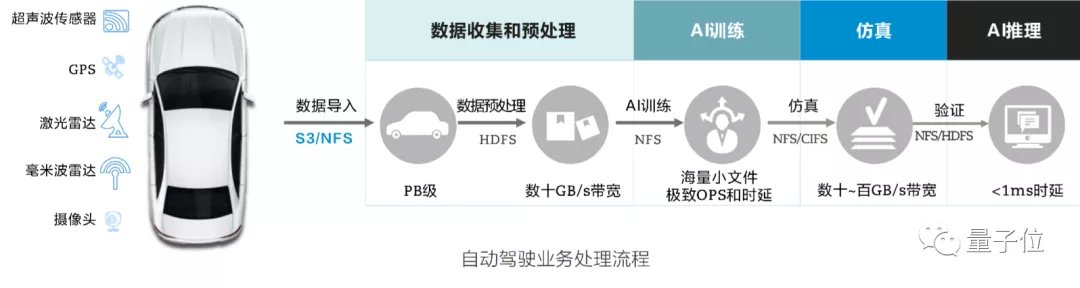
文章插图
从微观的分子化合物、神经细胞到中观的车辆、道路,再把视角拉大,研究宏观的地球、宇宙同样需要数据密集型超算。
能源勘探、气象预测、卫星遥感、天文观测的数据储存规模也在几十到几百PB,根据各自的特点还分别对超算的传输速度、是否需要AI接口、数据管理等问题提出不同的要求。
数据密集型超算该怎么建才能适应尽可能多的应用场景要求,就成了关键问题。
数据密集型超算该怎么建?诚然,超算在基因测序、自动驾驶、脑科学等场景上已展现出巨大潜力。
各个大国都想抢先于人去挖掘这块新土壤,由此也就产生了当下超算竞争日趋白热化的局面。
面对这样的形势,我们如何做才能抢占先机呢?
【 ssd|中国如何赢得新一轮超算竞赛?关键在向数据密集型超算转变】由中国计算机学会高性能计算专业委员会、国内各高校和超算中心、华为联合编写的《数据密集型超算技术白皮书》已经给出了一些切实可行的建议。
文章插图
《白皮书》认为,想要打赢这场算力上的“军备赛”,眼下我们应当从超算架构、网络传输、能耗等方面入手。
采用异构融合的新型 HPDA 架构首先,超算要考虑的核心问题还是算力的来源,这就要从处理器芯片说起。
如今的超算中心是把CPU、GPU、FPGA等硬件结合,让不同的计算单元来负责不同的计算任务,从而提高计算速度和处理能力。
但随之而来也会产生一个问题,就是资源、数据、应用上的孤岛现象,导致资源重复建设、闲置,造成能耗居高不下的问题。
所以,未来的超算中心,要把原来“散兵作战”的计算单元,再“大一统”起来。
让它们在发挥各自强项、快速完成任务的同时,还能听从调遣,最大化利用计算资源,并尽可能完成更多不同的任务。
这也就是《白皮书》中提到的——异构融合架构。
具体来看,就是要做到三个层面的统一:硬件上统一资源管理、统一数据存储;软件上统一资源调度。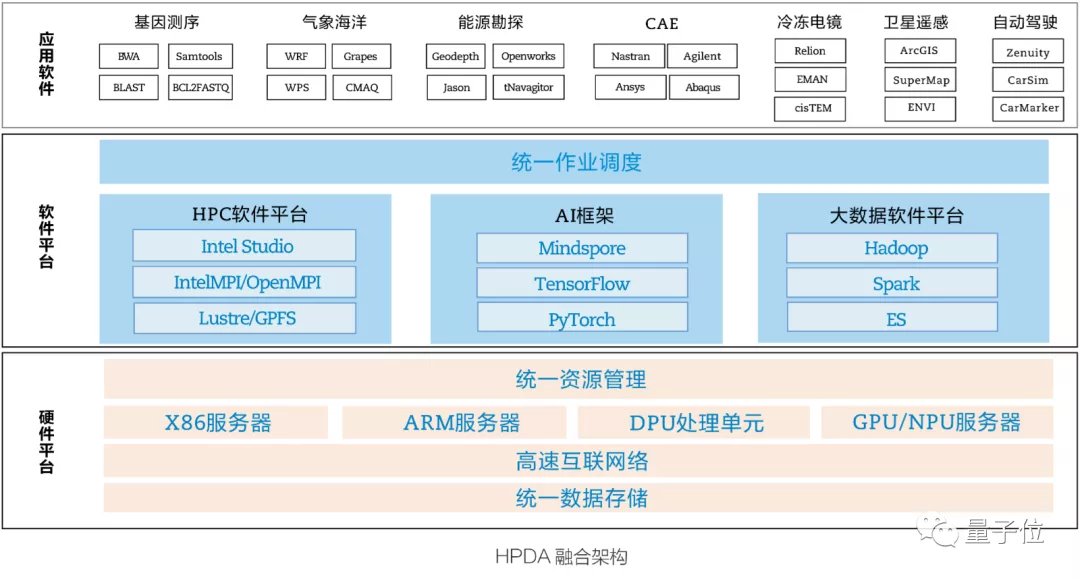
文章插图
打造存算分离的统一数据存储底座数据密集型超算以数据为中心,所以在计算单元之外,存储系统对超算运转速度也有巨大影响。
HPDA把HPC、大数据、AI融合,使得它的计算方式会和传统超算有所不同。
以发现新材料来举例,传统超算通过HPC仿真计算来发现新材料,HPDA则会用机器学习来实现,涉及AI模型的训练和推理。
这二者之间最大的差别就是,AI运算非常依赖数据。
具体工作过程中,大量计算时间都会消耗在等待数据从存储系统中读出或写入上。
如果沿用传统超算的存储系统,许多昂贵的计算节点都会处于空闲状态,造成资源利用不足的问题。
所以就要重新规划存储系统和计算系统。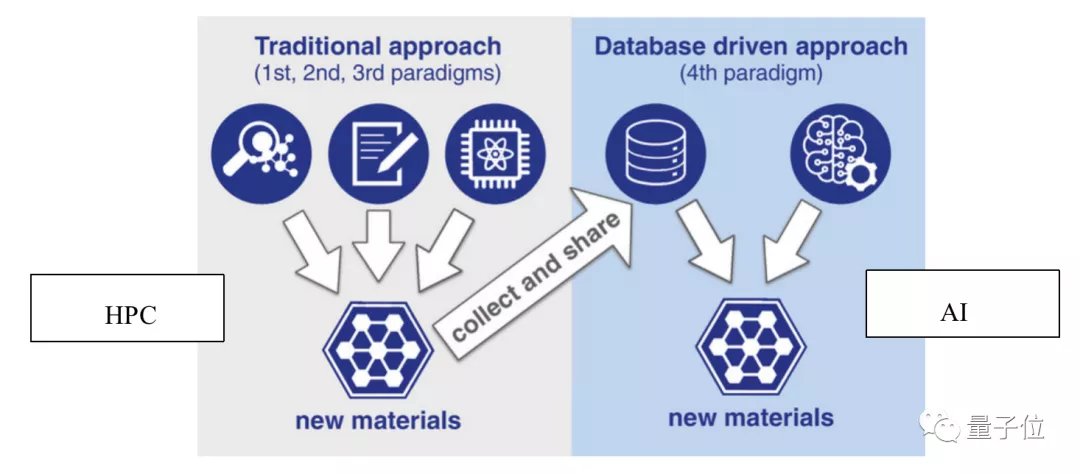
文章插图
《白皮书》对此提出了存算分离的概念。
也就是让所有计算节点都共享一个存储,并且让不同数据(文档、表格、图片等)之间可以互通、互访。
这样一来,超算执行不同任务时,计算节点从这个大的存储底座中找到需要的数据即可。
- 小米科技|不聊性能只谈拍照!新旗舰反向升级成潮流,拍照手机如何选?
- 产业|打造世界级产业地标 中国声谷冲刺5000亿产值
- 三星|试图挽回中国市场,国际大厂不断调价,从高端机皇跌到传统旗舰价
- 搜索引擎|淘宝运营系统出台春节打烊功能,淘宝运营商家该如何选择?
- 威刚展示 PCIe 5.0 SSD:连续读取14GB/s
- 小米科技|RTX3060的性能到底如何?相比RTX2060提升有多大?
- 蓝思科技|苹果与34家中国供应商断绝合作,央视呼吁:尽快摆脱对苹果依赖
- 他是“中国氢弹之父”,他的名字曾绝密28年,他叫于敏
- 短信|关于5G消息,中国移动取得新进展,微信该做准备了
- 一个时代的结束!中国移动:10086 App将于1月30日起