源1.0|源1.0开源开放,AI大模型再也不是“头部玩家”的奢侈品
最近,在微软联合全球八大研究院共同主办的首届微软研究峰会(Microsoft Research Summit 2021)上,微软董事长兼CEO萨提亚·纳德拉(Satya Nadella)表示,他现阶段正在关注的三个方向是:无处不在的计算、AI 大模型、虚拟在线,AI大模型这一方向,纳德拉关注“正在成为平台的大规模模型,这种大型模型背后的计算,如何继续构建系统。”
文章插图
就在近期,微软和英伟达联合发布Megatron-Turing自然语言生成模型(MT-NLG),拥有5300亿参数,堪称“巨无霸”,官方宣称同时夺得单体Transformer语言模型界“最大”和“最强”两个称号。
高度关注AI大模型的不只是微软,AI大模型已然掀起新一轮AI竞赛。
文章插图
大模型掀起新一波AI浪潮?2018年谷歌发布了拥有3亿参数的BERT预训练模型,它将自然语言处理能力推向了全新台阶,凭借出众的成绩屠榜各类AI榜单和测试数据集,BERT开启了AI的大模型时代,接下来几年,大模型的“擂台”各路挑战者接踵而至:
2019年OpenAI推出NLP大模型GPT-2,拥有15亿参数,可生成连贯的文本段落,可进行初步的阅读理解和机器翻译,英伟达则发布了83亿参数的威震天(Megatron-LM),谷歌又发布了110亿参数的T5,微软发布170亿参数的图灵Turing-NLG。
2020年OpenAI推出NLP大模型GPT-3,拥有1750亿参数,首次将大模型参数规模提升到千亿级,逼近人类神经元数量,其在传统的NLP能力外,还可以算术、编程、写小说、写论文摘要。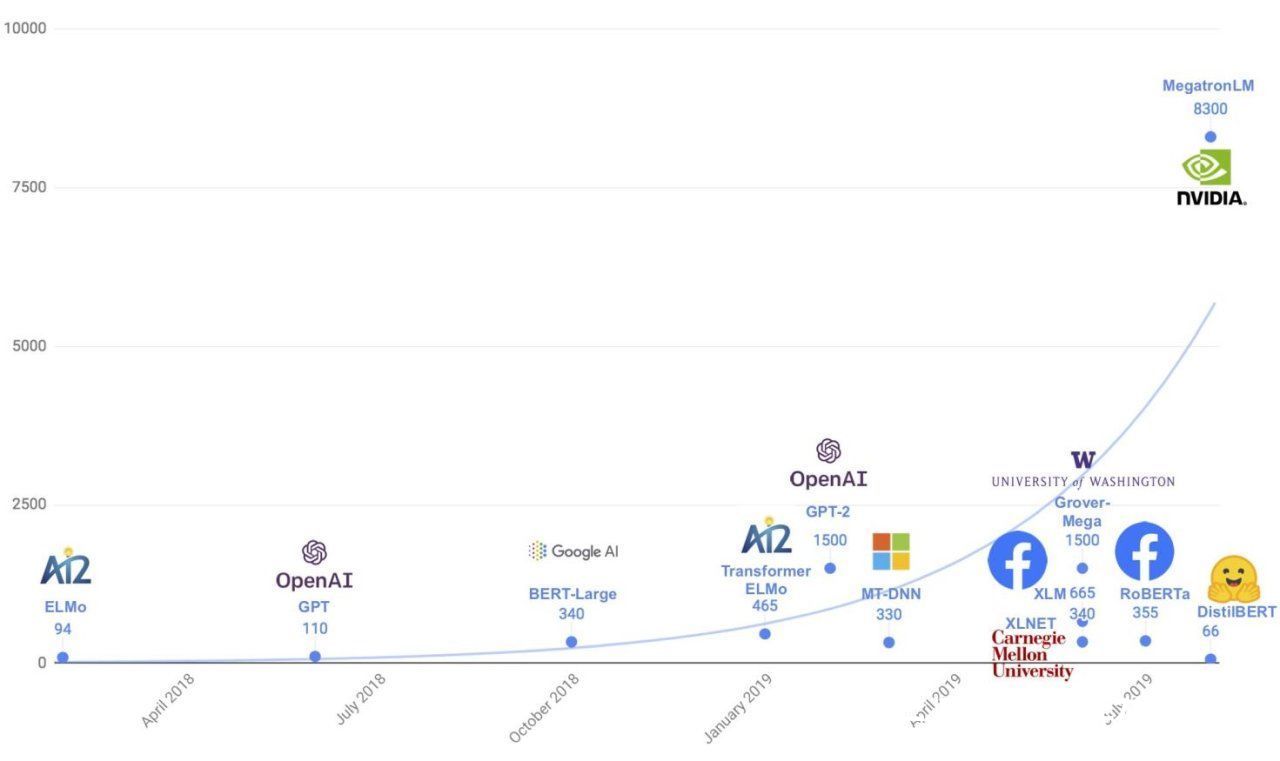
文章插图
2021年,国外的微软、英伟达、谷歌,国内的浪潮、华为和阿里……越来越多科技巨头都在布局AI大模型。其中国内AI大模型的代表之一是浪潮推出的“源1.0”,其拥有2457亿参数,参数量超越GPT-3,比肩“巨无霸”MT-NLG。源1.0在中文数据集拥有差异化优势,问鼎全球最大规模的中文AI巨量模型,它可以撰写对话、续写小说、新闻、诗歌、对联。在人工智能计算大会AICC2021现场,源1.0与观众互动对对联和“吟诗作赋”,通过互动形式让公众体验到AI大模型的威力。
文章插图
为何全球科技巨头不约而同瞄准了AI大模型?
首先从市场环境来看,深度学习高速发展十年来,AI技术正无处不在。当AI工业化阶段来临,AI要支撑更加广泛普适的场景,要支撑更大更复杂的AI计算需求,要实现从弱人工智能到强人工智能的升级,依靠传统训练模式已很难满足,具有“巨量数据、巨量算力、巨量算法”特性的AI大模型生逢其时。
文章插图
其次从技术原理来看,AI大模型本质是深度学习的“加强版”,通过给模型“填喂”大数据提高其自学习能力,进而具有更强的智能程度,比如在自然语言处理上表现更佳。
AI大模型更准确的称呼是“AI预训练大模型”,“预训练”字面意思很容易理解:预先训练好,这样应用开发者可得到相对现成的训练结果,基于此直接开发AI应用,不再需要从0到1训练数据、建立模型。
AI大模型通过堆叠数据集“贪婪式”地训练模式,拥有较强的通用性,理论上可泛化到多种应用场景,而小样本或零样本的技术实现,则可让应用开发者快速基于其构建工程应用。
最后从发展潜力来看,虽然AI大模型有被诟病的地方,比如数据多不一定就准、回报存在不确定性、依然存在认知缺陷……不过,全球巨头都意识到AI大模型不确定性背后是更大的可能性。AI大模型最终会带来什么样的成果无人知晓,它可能是强人工智能的终极模式,也可能只是过渡手段,但已经越来越清晰地呈现出魅力:在NLP等领域展现出肉眼可见的优势,是人类当前看到的最接近强人工智能的训练方式,是推进AI认知智能突破、挑战人类智能的关键。
- 供冷供热约占全球终端能源消耗的50%|吸附式制冷材料研究取得进展
- 运营商|手机六连靓号被运营商回收,拒绝补贴20万,运营商:浪费资源
- 化州市富美家电维修店整合行业招商运营资源的专业平台
- it|浪潮宣布加入 OpenCloudOS 操作系统开源社区
- 本文来源于微信公众号有趣青年(ID:v_danshen)“一分钟聊‘青年理想城市’”互动...|“我不敢在微信上表白。”
- 锐龙|为什么AMD只推出一款锐龙7 5800X3D?因为资源都优先给Milan-X了
- 蔚来发布Aspen 3.1.0更新 强化蓝牙链接功能/增加动态透明底盘
- 昌江区珠山区区县服务商整合行业招商运营资源的专业平台
- 买斗整合行业招商运营资源的专业平台
- 来源:楚天交通广播、微博、中新经纬版权归原作者所有|热搜第一,微信上线新功能!