模型|超过谷歌 阿里达摩院AI预训练模型M6参数破10万亿
新京报贝壳财经讯(采访人员 罗亦丹)11月8日,贝壳财经采访人员从阿里巴巴达摩院获悉,其多模态大模型M6最新参数已从万亿跃迁至10万亿,规模超过了谷歌、微软此前发布的万亿级模型,成为全球最大的AI预训练模型。
贝壳财经采访人员观察到,2021年以来,AI训练模型的规模不断扩大。据不完全统计,这些大模型包括年初华为发布的1000亿参数盘古大模型、1.6万亿参数的Google switch transformer模型、1.75万亿参数的智源悟道2.0智能模型、1.9万亿参数的快手精排模型等。其中,阿里达摩院M6模型上一次公布的参数规模为1万亿。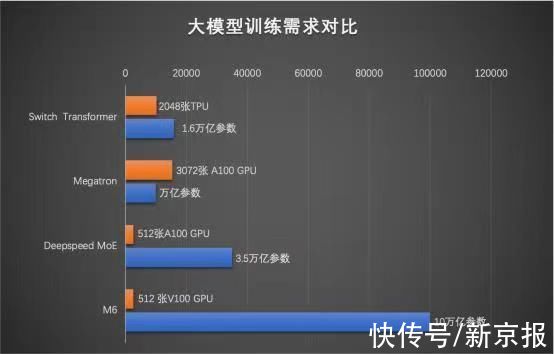
文章插图
据了解,与传统AI相比,大模型拥有成百上千倍“神经元”数量,且预先学习过海量知识,表现出像人类一样“举一反三”的学习能力。因此,大模型被普遍认为是未来的“基础模型”,将成下一代AI基础设施。
“近年来人工智能的发展应该从家家户户‘大炼模型’的状态逐渐变为把资源汇聚起来,训练超大规模模型的阶段,通过设计先进的算法,整合尽可能多的数据,汇聚大量算力,集约化地训练大模型,供大量企业使用,这是必然趋势。”北京大学信息科学技术学院教授黄铁军此前告诉贝壳财经采访人员。
需要注意的是,训练大模型的算力成本相当高昂,如训练1750亿参数语言大模型GPT-3所需能耗,相当于汽车行驶地月往返距离。对此,达摩院表示,M6使用512 GPU在10天内即训练出具有可用水平的10万亿模型,相比去年发布的大模型GPT-3,M6实现同等参数规模,能耗减至其1%,达摩院透露,实现能耗减少的技术原理包括通过更细粒度的CPU offload、共享-解除算法等。
据了解,M6是达摩院研发的通用性人工智能大模型。目前,达摩院联合阿里云推出了M6服务化平台,为大模型训练及应用提供完备工具,算法人员及普通用户均可使用平台。
达摩院智能计算实验室负责人周靖人表示,“接下来,我们将深入研究大脑认知机理,致力于将M6的认知力提升至接近人类的水平,比如,通过模拟人类跨模态的知识抽取和理解方式,构建通用的人工智能算法底层框架;另一方面,不断增强M6在不同场景中的创造力,产生出色的应用价值。”
【 模型|超过谷歌 阿里达摩院AI预训练模型M6参数破10万亿】校对 柳宝庆
- 三星|三星手机Soc搭载AMD Radeon GPU曝光,运行频率超过苹果A15
- 微信聊天最令人头疼的场景是什么?一定有人会说是对方发来一连串语音还都是超过30秒的长消息...|终于!微信上线万众期待的新功能!网友:总算等到了
- 微信聊天最令人头疼的场景是什么?一定有人会说是对方发来一连串语音还都是超过30秒的长消息...|微信、支付宝,上线新功能
- 高通骁龙|高通骁龙8扎堆上市,3款国产旗舰性能强悍,性价比超过iPhone13
- 微信聊天最令人头疼的场景是什么?一定有人会说是对方发来一连串语音还都是超过30秒的长消息...|终于!微信新增语音暂停功能,60秒长语音不用重头再
- Pixel|2800元的谷歌Pixel 5a成老外眼中最好的手机之一:可惜没人关注
- 谷歌Pixel|谷歌Pixel 6 Pro经常没信号:官方推送更新修复
- Java|假如让谷歌浏览器进入中国市场,国产浏览器会受到很大影响吗?
- Jeff De2021谷歌年度 Jeff
- Pixel|致敬OPPO Find N!谷歌折叠屏曝光:价格不到11000元