样本|只需1/500数据便可掌握Atari游戏!清华叉院助理教授提出小数据RL模型,引爆AI社区

文章插图
编辑 | 青暮
文章插图
文章插图
现在,就让我们隆重的介绍下本文的主角—— EfficientZero。
EfficientZero算法是在清华大学交叉信息研究院高阳团队的新研究《使用有限数据掌控Atari游戏》( Mastering Atari Games with Limited Data)中提出的。EfficientZero的性能接近DQN(Deep Q-Learning)在 2 亿帧时的性能,但消耗的数据却减少了500 倍!它能够在贴近现实复杂情况的Atari(雅达利)游戏中,从零训练并只需两个小时,就可达到同等条件下人类平均水平的190.4%,或116.0%的中值性能。
文章插图
论文链接:https://arxiv.org/abs/2111.00210#
样本效率一直是强化学习中最“令人头疼”的挑战,重要的方法需要数百万(甚至数十亿)环境步骤来训练。一种从MuZero模型改进而来的高效视觉RL算法—— EfficientZero,该模型从零开始训练,最终在Atari中仅用两个小时的训练数据上就超过了经过相同条件下的的人类平均水平。
MuZero是通过将基于树的搜索与经过学习的模型相结合,可以在一系列具有挑战性和视觉复杂的领域中,无需了解基本的动态变化即可实现出色性能。AI科技评论在以往的文章中对MuZero有过报道:DeepMind又出大招!新算法MuZero登顶Nature,AI离人类规划又近了一步。那为什么会选择Atari游戏呢?Atari 游戏场景繁多,规则各异,一定程度上贴合现实复杂环境,因此长期被当作验证强化学习算法在多因素环境下的性能测试标准。EfficientZero的低样本复杂度和高性能可以使强化学习更接近现实世界的适用性。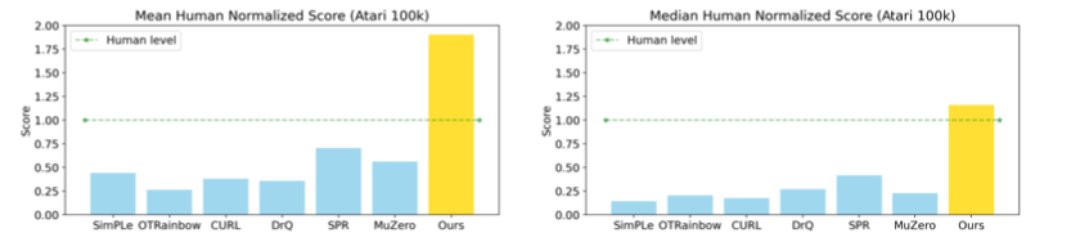
文章插图
如图所示,EfficientZero在人类平均标准得分中位数上分别比之前的SoTA性能出色170%和180%。是第一个在Atari 100k基准上优于人类平均性能的算法。
强化学习在挑战性的问题上取得了巨大的成功。如2015年DeepMind研发的DQN网络 、击败了中国围棋世界冠军柯洁的AlphaGo、和会在Dota2中打团战的OpenAI Five等等。但这些都是站在巨大数据量的“肩膀上”训练出来的策略。像AlphaZero从国际象棋小白到顶尖高手需要完成2100万场比赛,一个职业棋手每天大约只能完成5场比赛,这意味着人类棋手要11500年才能拥有相同的经验值。
在模拟和游戏中应用RL算法,样本复杂性不成阻碍。当涉及到现实生活中的问题时,例如机器人操作、医疗保健和广告推荐系统,在保持低样本复杂性的同时实现高性能是能否可行的至关钥匙。
- 产业|打造世界级产业地标 中国声谷冲刺5000亿产值
- 华为鸿蒙系统|华为偷偷上架新机,鸿蒙系统+5000mAh大电池,仅售1399元
- 能量密度达500Wh/kg!日本开发出新款锂空气电池
- 骁龙855|从3499元跌至1190元,5000mAh+骁龙855,适合玩游戏
- 44岁接手亏损超500万厂子,他却靠火腿肠雄起,缔造600亿
- 华为|Mate50也不香了,麒麟9000+5000万徕卡三摄,华为老旗舰降至冰点
- 华为|华为商城再次上架5G手机,5000毫安+128GB,价格只要1699元起
- 测试|解码自动驾驶商业化进阶的亦庄样本
- 恶意软件|报告称 2021 年 Linux 的恶意软件样本数量增加了 35%
- 华为上架新机,搭载麒麟芯片,5000mAh仅售1399元