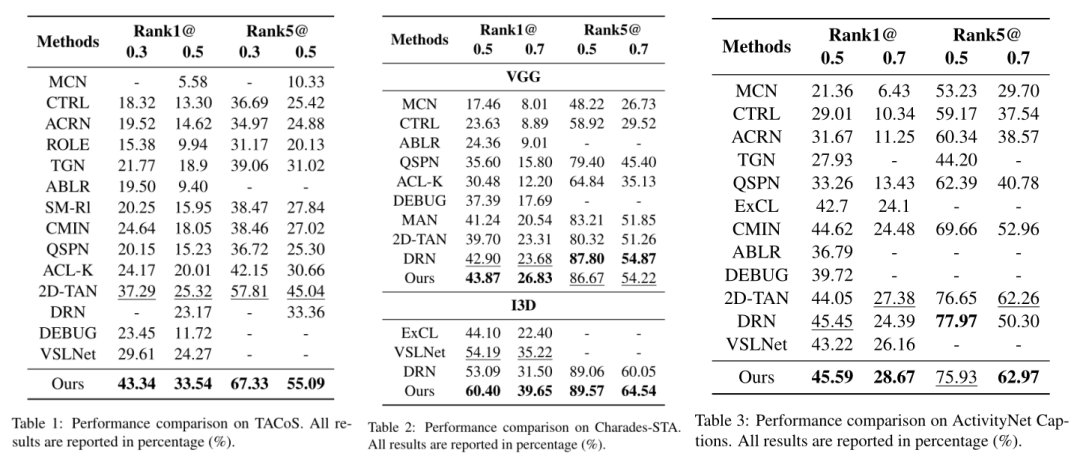
本文在3个常见数据集TACoS、Charades-STA、ActivityNet Captions上,采用了Rank n@m评价指标,与以往的工作进行了对比,在3个数据集上基本都取得了SOTA的表现。
文章插图
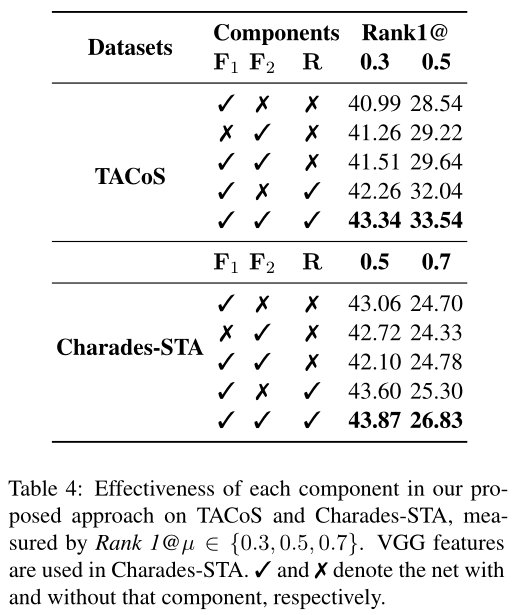
为了突显出模型中每个模块的重要性,研究者们做了消融实验,从结果来看,同时考虑视频片段和句子的关系,以及视频片段和单词的关系,比单独考虑这两者带来的收益要多。当同时构建不同视频片段之间的关系时,模型能够更加精准地对视频片段进行定位。
文章插图
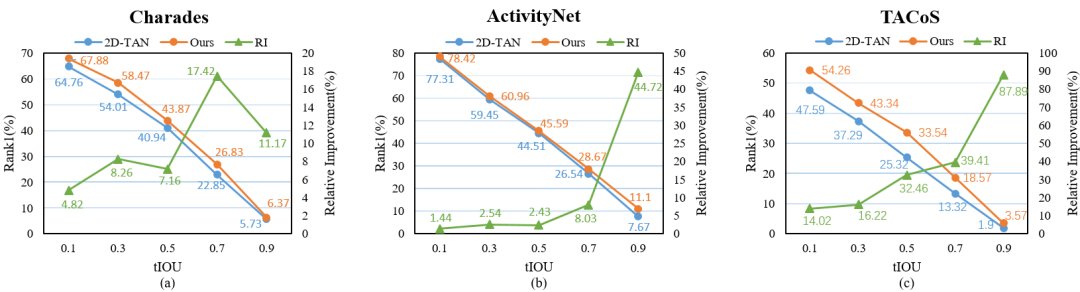
研究者们还与之前SOTA模型2D-TAN比较了在不同IoU上的相对提升率,可以发现,在越高的IoU上,本文的RaNet提升得更加明显。
文章插图
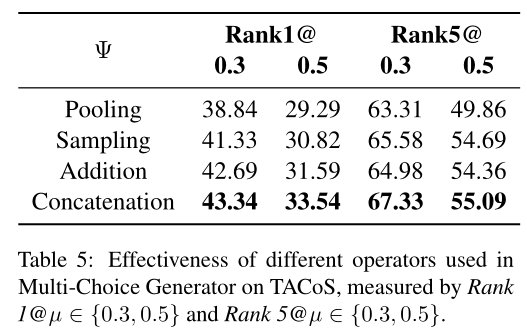
研究者们比较了Pooling、Sampling、Addition、Concatenation这四种不同的视频片段特征的生成方式,实验发现更加关注边界特征的Concatenation操作表现更好。
文章插图
不同word embeddings的影响:
为了探寻不同的词向量编码对实验结果对的影响,研究者们还比较了不同word embeddings的表现,发现越强的语言表征更有益于模型精准地定位视频片段。
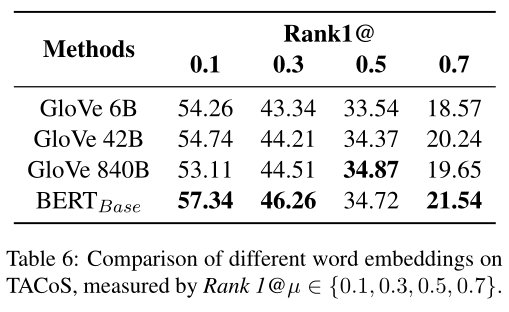
文章插图
研究者们还展示了模型在TACoS数据集上的参数量和FLOPs,并和之前的2D-TAN模型进行了对比,由于在构建视频片段关系的模块中本文采用的是稀疏连接的图网络模型,所以参数量大大减小,效率得到了提升。
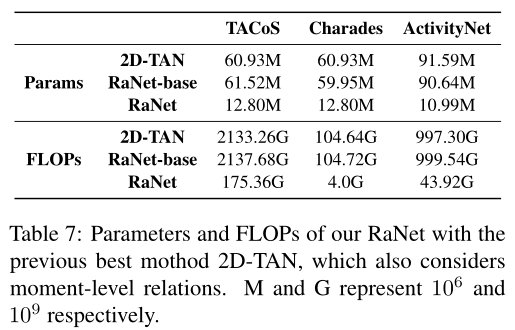
文章插图
最后,研究者们还通过可视化的例子展现了模型的能力。

文章插图
针对基于语言查询的视频片段定位这个任务,云从-上交的联合研究团队提出了,将视频片段定位类比为自然语言处理中的多项选择阅读理解,同时建模了视频片段-句子层面和视频片段-单词层面的关系,并且提出了一种稀疏连接的图网络高效地建模了不同视频片段之间的关系,在公开数据集上取得了SOTA表现。
更多的技术细节请参考[RaNet: arxiv paper](https://arxiv.org/abs/2110.05717)。
[1] Songyang Zhang, Houwen Peng, Jianlong Fu, and Jiebo Luo. 2020b. Learning 2d temporal adjacent networks for moment localization with natural language.In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pages 12870–12877.[2] Mengmeng Xu, Chen Zhao, David S. Rojas, Ali Thabet, and Bernard Ghanem. 2020. G-tad: Sub-graph localization for temporal action detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).[3] Zilong Huang, Xinggang Wang, Lichao Huang, Chang Huang, Yunchao Wei, and Wenyu Liu. 2019. Ccnet: Criss-cross attention for semantic segmentation. In2019 IEEE/CVF International Conference on Computer Vision (ICCV), pages 603–612.
文章插图
雷锋网