deepmind|DeepMind打造AI游戏王!挑战各种最强棋牌AI,战斗力惊人( 二 )
要玩好完全的信息游戏,需要相当多的预见性和计划。玩家必须处理他们在棋盘上看到的东西,并决定他们的对手可能会做什么,同时努力实现最终的胜利目标。不完全信息游戏则要求玩家考虑隐藏的信息,并思考下一步应该如何行动才能获胜,包括可能的虚张声势或组队对抗对手。
DeepMind称,Player of Games是首个“通用且健全的搜索算法”,在完全和不完全的信息游戏中都实现了强大的性能。
Player of Games(PoG)主要由两部分组成:1)一种新的生长树反事实遗憾最小化(GT-CFR);2)一种通过游戏结果和递归子搜索来训练价值-策略网络的合理自对弈。
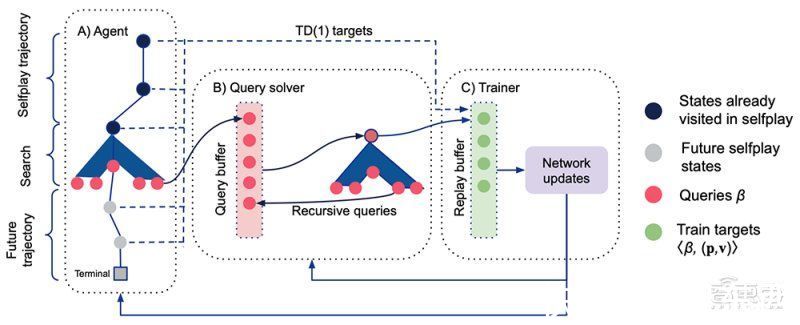
文章插图
Player of Games训练过程:Actor通过自对弈收集数据,Trainer在分布式网络上单独运行
在完全信息游戏中,AlphaZero比Player of Games更强大,但在不完全的信息游戏中,AlphaZero就没那么游刃有余了。
Player of Games有很强通用性,不过不是什么游戏都能玩。参与研究的DeepMind高级研究科学家马丁·施密德(Martin Schmid)说,AI系统需考虑每个玩家在游戏情境中的所有可能视角。
虽然在完全信息游戏中只有一个视角,但在不完全信息游戏中可能有许多这样的视角,比如在扑克游戏中,视角大约有2000个。
此外,与DeepMind继AlphaZero之后研发的更高阶MuZero算法不同,Player of Games也需要了解游戏规则,而MuZero无需被告知规则即可飞速掌握完全信息游戏的规则。
在其研究中,DeepMind评估了Player of Games使用谷歌TPUv4加速芯片组进行训练,在国际象棋、围棋、德州扑克和策略推理桌游《苏格兰场》(Scotland Yard)上的表现。
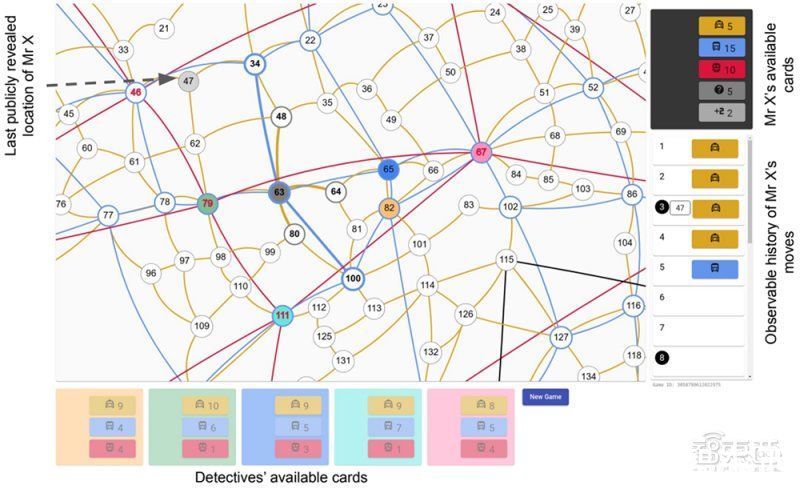
文章插图
苏格兰场的抽象图,Player of Games能够持续获胜
在围棋比赛中,AlphaZero和Player of Games进行了200场比赛,各执黑棋100次、白棋100次。在国际象棋比赛中,DeepMind让Player of Games和GnuGo、Pachi、Stockfish以及AlphaZero等顶级系统进行了对决。
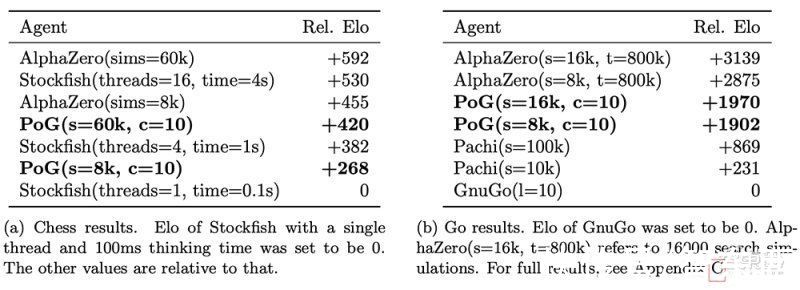
文章插图
不同智能体的相对Elo表,每个智能体与其他智能体进行200场比赛
在国际象棋和围棋中,Player of Games被证明在部分配置中比Stockfish和Pachi更强,它在与最强的AlphaZero的比赛中赢得了0.5%的胜利。
尽管在与AlphaZero的比赛中惨败,但DeepMind相信Player of Games的表现已经达到了“人类顶级业余选手”的水平,甚至可能达到了专业水平。
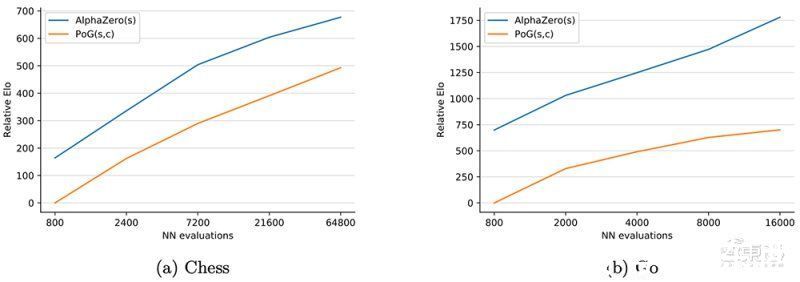
文章插图
Player of Games在德州扑克比赛中与公开可用的Slumbot对战。该算法还与Joseph Antonius Maria Nijssen开发的PimBot进行了苏格兰场的比赛。
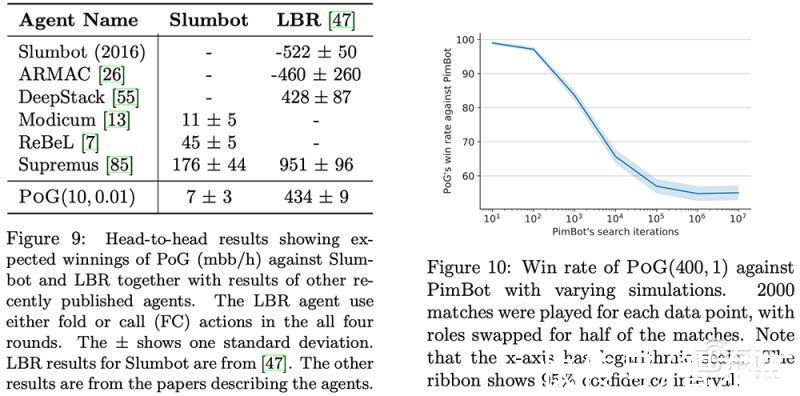
文章插图
不同智能体在德州扑克、苏格兰场游戏中的比赛结果
结果显示,Player of Games是一个更好的德州扑克和苏格兰场玩家。与Slumbot对战时,该算法平均每hand赢得700万个大盲注(mbb/hand),mbb/hand是每1000 hand赢得大盲注的平均数量。
同时在苏格兰场,DeepMind称,尽管PimBot有更多机会搜索获胜的招数,但Player of Games还是“显著”击败了它。
三、研究关键挑战:训练成本太高施密德相信Player of Games是向真正通用的游戏系统迈出的一大步。
实验的总体趋势是,随着计算资源增加,Player of Games算法以保证产生更好的最小化-最优策略的逼近,施密德预计这种方法在可预见的未来将扩大规模。
“人们会认为,受益于AlphaZero的应用程序可能也会受益于游戏玩家。”他谈道,“让这些算法更加通用是一项令人兴奋的研究。”
- 产业|打造世界级产业地标 中国声谷冲刺5000亿产值
- DeepMind首席科学家:比起机器智能,我更担心人类智能造成的灾难
- 多家银行宣布打造AI数字员工?虚拟人风口下银行也不要真人了?
- |既能打造你的品牌又能促进销售的广告宣传方法?
- 美通社|驭势科技与Teksbotics打造无人驾驶递送车现身沙特 | 阿卜杜拉
- 单片机|OPPO最新实验室曝光:与华中科技大学联合打造,将加速新技术研发
- Intel找台积电打造专属3nm的工厂:并非短期合作?
- 新快报讯 记者张磊报道 2021年三季度|线上线下双“IQ”赋能,凯迪拉克LYRIQ打造更高维度的用户互联
- 社区矫正中心|邯山区司法局推进“智慧社区矫正中心”建设,打造实战平台,提升矫正
- 圆通速递|无人驾驶递送车现身沙特,驭势科技与Teksbotics强强联合打造