文章插图
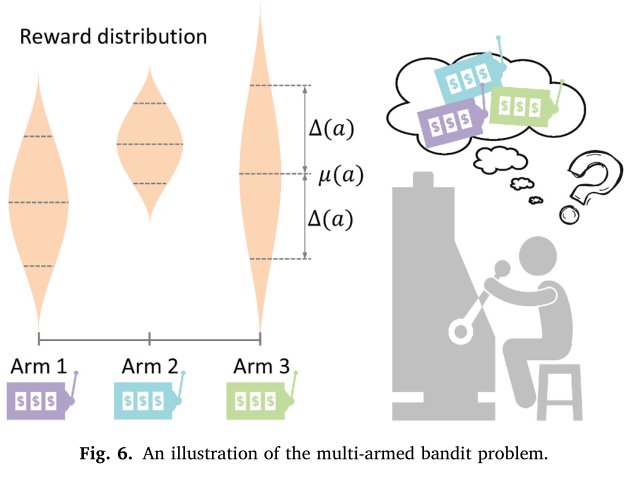
多臂机在CRS的应用
待推荐的物品可以看做MAB中的摇臂,系统可以选择当前用户偏好的物品,也可以冒险尝试用户未知偏好的物品。传统MAB方法将物品看做相互独立的,并且忽略了物品特征信息,如属性。Li等人提出了第一个使用文本信息的多臂机算法,类似于协同过滤算法,利用了用户和物品的特征信息。
多臂机算法能够在线学习,几轮交互之后便能更新用户的偏好,调整对话策略。
Evaluate CRSs
对CRS的评价分为两类。第一类是Turn-level的评价,评估每轮的输出,是一个监督预测问题;第二类是Conversation-level的评价,评估多轮对话的技巧,是一个序列决策问题。
数据集和工具
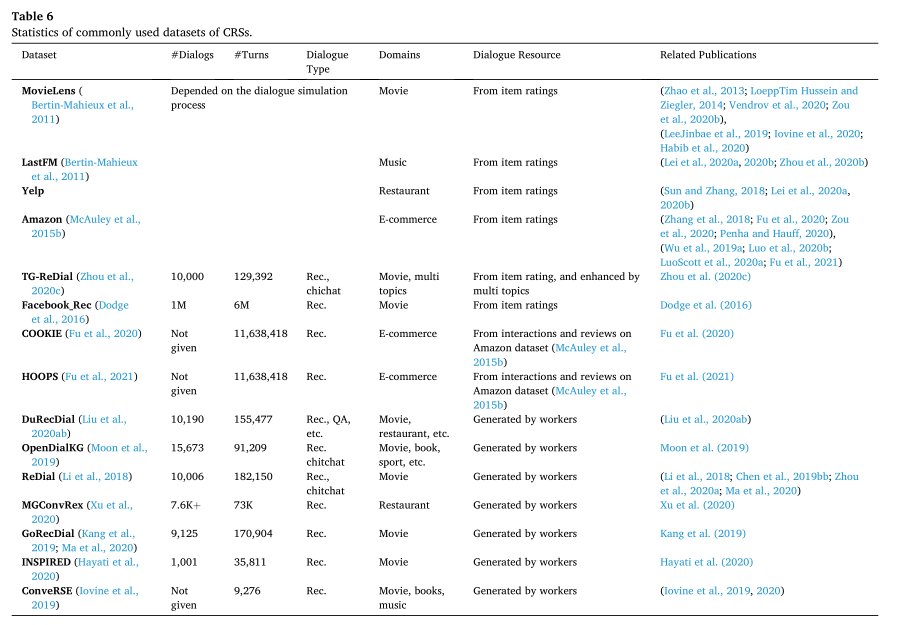
常用CRS数据集
文章插图
虽然数据集数量较多,但是仍不足以开发能够工业应用的CRS。除了数据集规模过小,还有就是数据集比较有规则,难以适应真实世界的复杂情况。
常用工具
zhou等人实现了开源工具包,CRSLab。工具包包含了三个子任务:推荐,对话,策略,对应了CRS的三个部分。一些模型通过这三个任务实现。工具包还包含评估模块,不仅能够进行自动评估,还能通过交互接口进行人工评估。
Turn-level evaluation
语言生成的评价
两个常用指标是BLEU和Rougue。BLEU衡量的是生成词的准确率,即生成的词有多少出现在了正确答案上。Rougue衡量的是生成词的召回率,正确答案的词在生成回答中出现了多少。但是这两个指标是否能够有效评价语言生成任务具有争议,因为这两个指标只能评价词汇变化,不能评价语义和语法上的变化。另外,CRS模型的任务不是预测最可能的回答,而是对话的长期有效。所以,其他的一些指标,如多样性、连续性,反映了用户的满意程度可能更加适合评估CRS。
推荐的评价
推荐系统评价分为基于评分和基于排序的评价。基于评分的评价中,用户反馈是评分,如1-5分。常用的评价指标有MSE和RMSE;基于排序的评价中,用户反馈可以是隐式的点击,购买等操作。只需预测物品的相对顺序即可,在实际情况更常用。常见的基于排序的指标有点击率、F1分数,MRR、MAP等。
Conversation-level evaluation
不同于Turn-level evaluation,Conversation-level evaluation没有中间的监督信号。因此需要在线用户或者利用历史数据进行用户模拟。
在线用户测试可以直接根据用户的真实反馈进行评价。常用的指标有,平均轮数(AT)和recommendation
success rate (SR@t)。平均轮数(AT)指系统为了成功完成推荐所需对话轮数,而SR@t是指有多少对话在第t轮完成了推荐。Off-policy evaluation也称为反事实推理。问题会设计成反事实问题,比如,如果我们用\pi_{\theta}代替\pi_{\beta},会发生什么?
用户模拟通常有4个技巧:
- 1,直接使用用户的交互历史。将人类交互数据集的一部分作为测试数据集。
- 2,估计用户在所有物品的偏好。由于数据集中包含的物品有限,数据集之外的物品往往被视为不喜欢的物品。为此,最好是估计用户在所有物品的偏好。给定物品和它的信息,模拟用户在该物品上的偏好。
- 3,从所有用户的评价抽取。除了用户行为之外,许多电商平台包含很多文本评价数据,物品的评价会显式地提及物品的属性,能够反映用户在该物品上的偏好。但是,物品的缺点并不能解释用户为何购买该物品,因此只有积极的评价,才会被认为用户选择该物品的原因。
- 物联网|?内容创作者:要明白文章首先是写给推荐系统看的!
- iPad|ipad平替电容笔推荐;2022最新性价比电容笔推荐
- oppo reno|打算年底前换手机?追求游戏、拍照,我只推荐这款国产手机
- 裁员潮|内容推荐系统:你的文章至少要先让它明白
- CPU|推荐4款千元机,2022年公认“值得买”,好评率95%
- 一加科技|过年回家换新手机推荐哪款?三个理由说服你入手一加10 Pro
- 蓝牙耳机|什么蓝牙运动耳机好? 高性价比蓝牙耳机推荐
- 空调|对话海信空调冯涛:空调到空气的战略革新,相信用户会有正确选择
- 高通骁龙|千元机最适合的是哪款 目前最值得入手的千元机 我就推荐这四款
- 「1月行情」老旗舰送背刺,599到12999元手机推荐