萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
老觉得AI和你说话前言不搭后语?
【 lAI说话“前言不搭后语”?用逻辑规则教它们读懂文章丨字节AI Lab】为了避免AI出现这样的情况,通常我们在NLP中会用到关系抽取技术,用于从非结构化的文本中抽取出结构化的知识,即所谓的关系三元组。
例如这句话:
英国的哈里王子与他美国的同伴梅根订婚了。

文章插图
△句子级别的关系抽取示例
可以从中抽取2个关系三元组:
1、哈里、皇室成员、英国
2、哈里,订婚于,梅根
目前,句子级别的关系抽取已经比较成熟,但文档级别或是篇章级别的关系抽取却要更难。
不少AI,往往没办法从整篇文章中熟练地提取上下文信息。
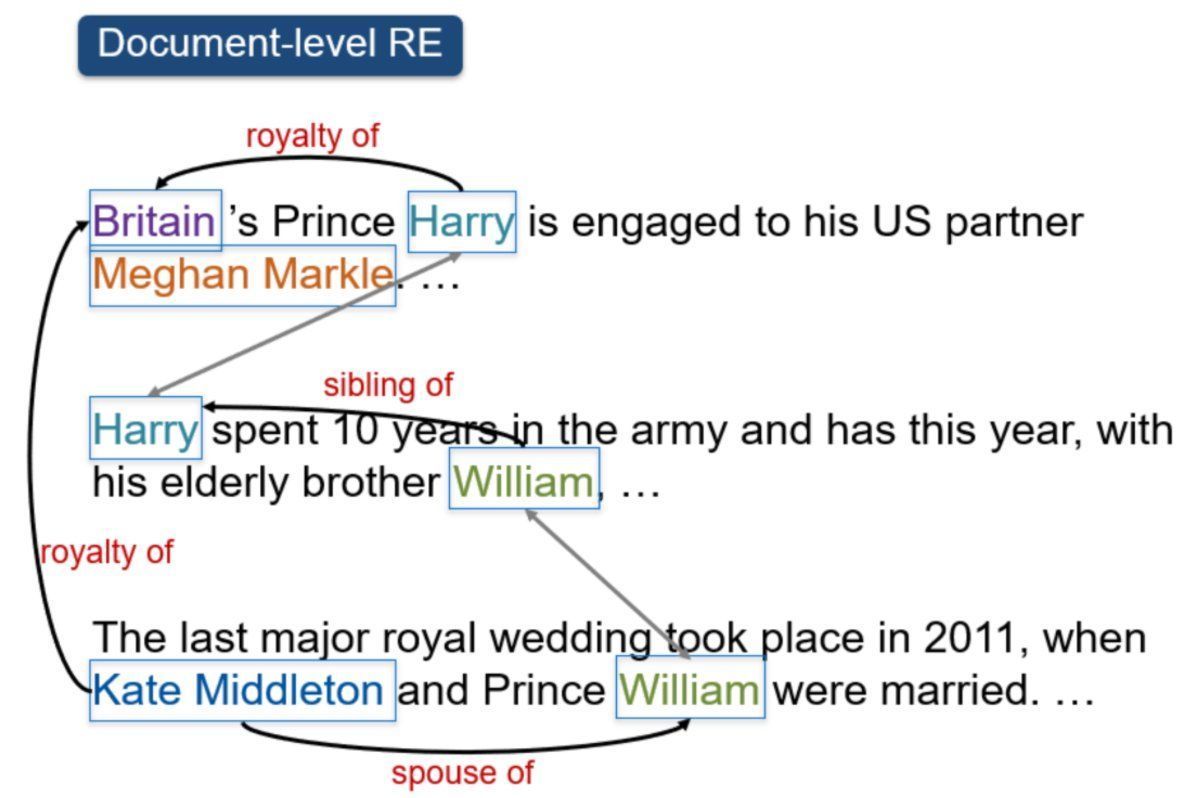
文章插图
△文档级别的关系抽取示例
为此,字节跳动AI-Lab提出了一个文档级的关系抽取框架LogiRE,专门来解决这种“长难篇章”的信息理解挑战。

文章插图
一起来看看。
此前方法的局限性此前,大部分关系抽取的方法,通常可以被分为两类:“基于序列”或“基于图”。
其中,基于序列的工作一般借助预训练语言模型,得到每个词的表示,接着使用各种池化的方法得到实体对的表示,再基于这样的表示做关系分类。
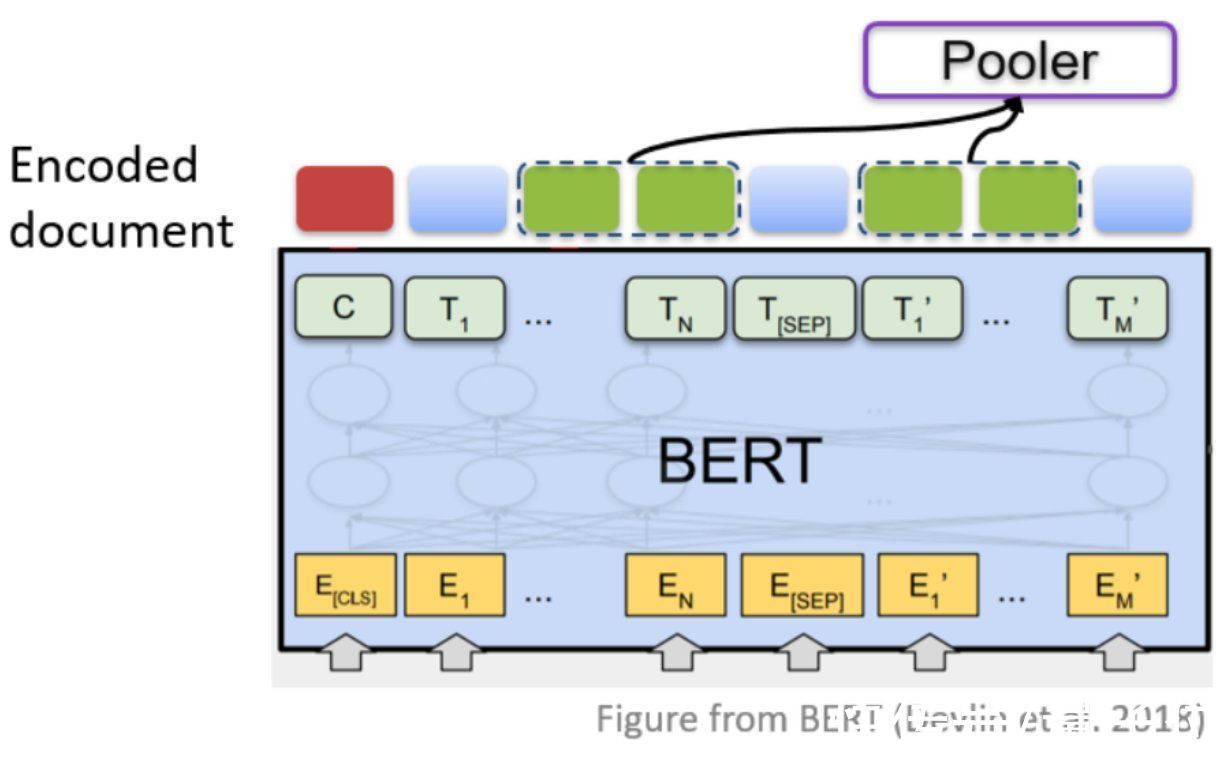
文章插图
基于图的工作,则依赖于一个显示的图结构,通过构建一个图来连接文档中的实体提及,实体以及句子等,之后再利用图神经网络,在这些图上进行消息传递,抽取特征并进行分类。
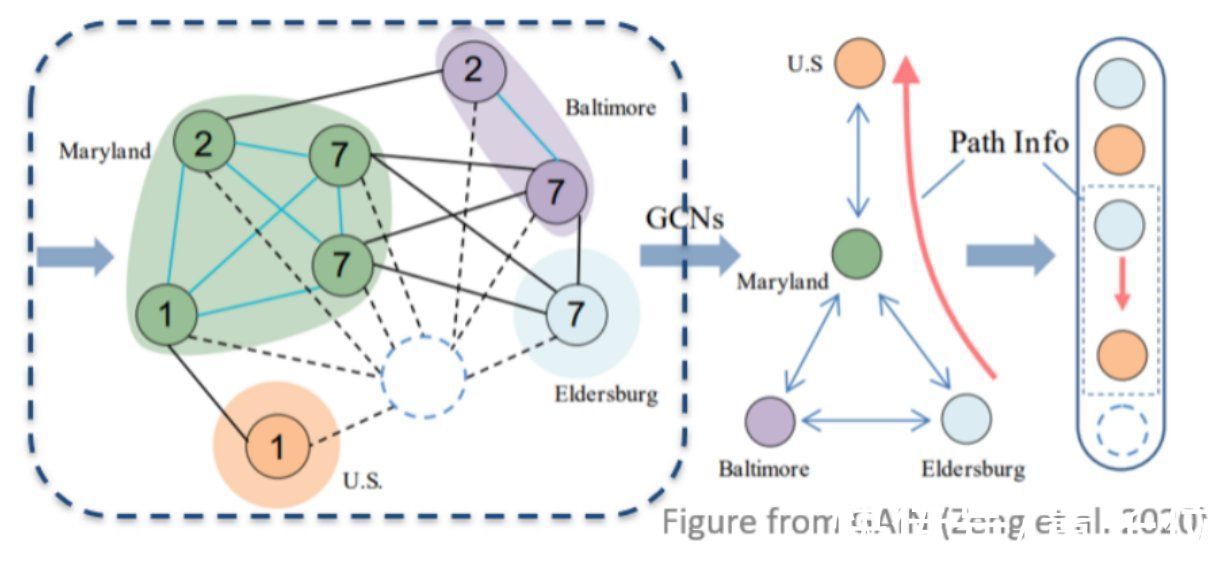
文章插图
然而,这两类方法都存在一些局限性。
一方面,序列模型在处理长距离依赖时会遇到困难,基于图的模型虽然一定程度上缓解了这一问题,但图的构建却需要人工确定的规则先验,并且只包含一些粗粒度的信息。
另一方面,他们都只能隐式地通过共享的特征抽取来实现对实体关系之间交互的建模。
在这种情况下,字节AI Lab的研究人员想到了一个新方法:逻辑规则。
用“逻辑规则”来做关系抽取这个新提出的框架名叫LogiRE,结合逻辑规则与深度神经网络进行文档级关系抽取,核心是作为隐变量的逻辑规则。
其中,逻辑规则连接了框架中的两大构成单元:规则生成器 (Rule Generator) 和关系抽取器 (Relation Extractor)。整个框架的优化,采用的是迭代式的EM算法。
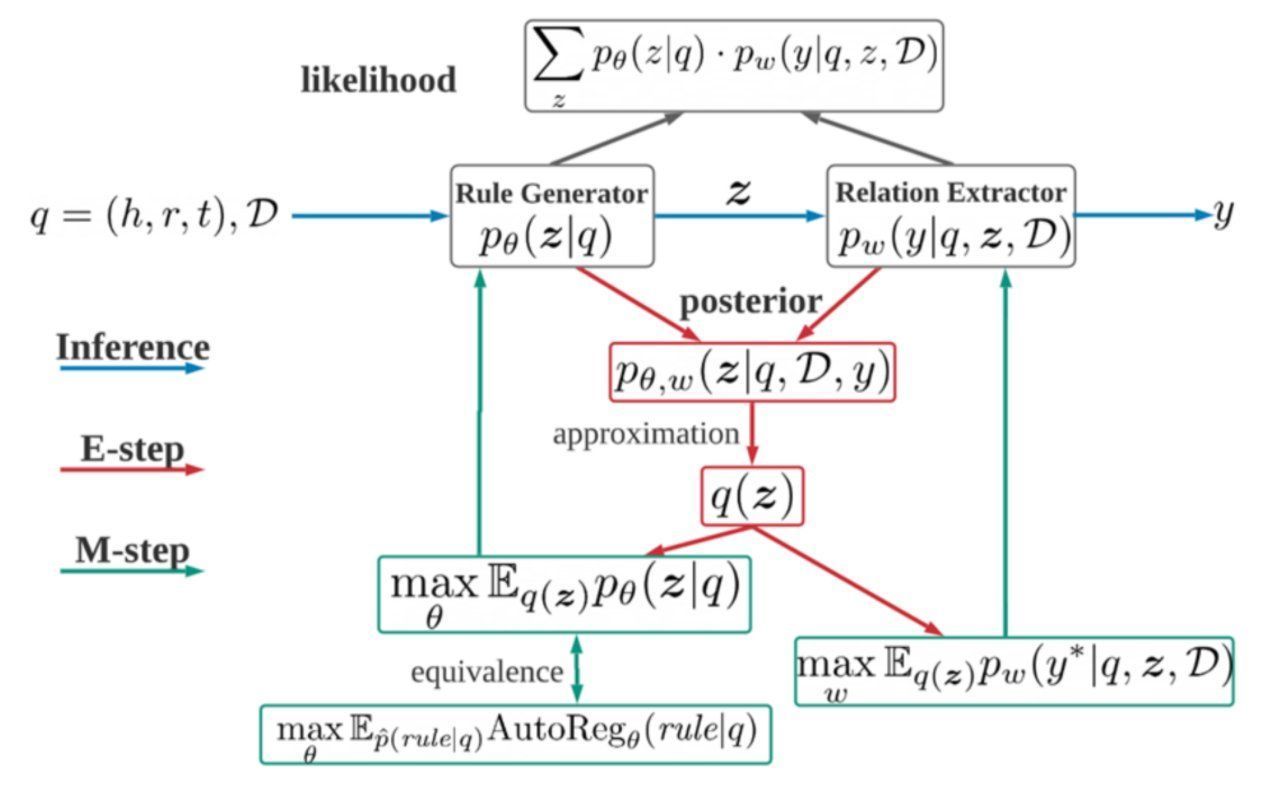
文章插图
具体来说,逻辑规则被形式化地定义成这样:
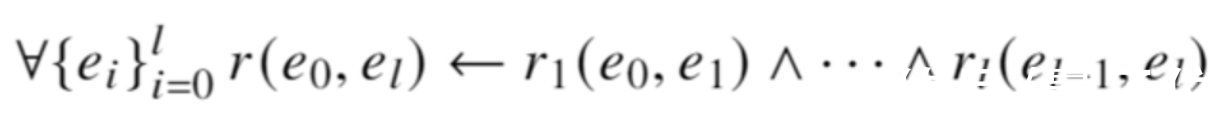
文章插图
对应到关系抽取中,关系对应规则中的“谓词”,实体对应“变量”。
对于基于生成规则的关系抽取,当定义规则对应的分数为确定头实体和尾实体后,在不同的中间实体选择下最高路径得分。
其中,每一条实例化路径的分数,由路径上每一个三元组分数的乘积确定。
三元组的分数可以由任意的关系抽取backbone模型给出。规则组中所有分数,在经过基于sigmoid的逻辑融合之后,即得到对目标三元组的最终概率得分。
实验结果表明,LogiRE无论是在关系抽取的性能 (ign F1,F1) ,还是逻辑自洽性 (logic) 上都超过基线。
- 苹果|库克压力确实大,在众多国产厂家对标下,iPhone13迎来“真香价”!
- 京东正式上线“年礼无忧”服务
- 央视公开“支持”倪光南?柳传志该醒悟了
- 小米 11 Ultra 内测 NFC“读写勿扰”与“解锁后使用”功能
- 造车|苹果造车一波三折,缺了一家“富士康”
- 他是“中国氢弹之父”,他的名字曾绝密28年,他叫于敏
- iPhone|iphone14价格被曝!“胶囊”挖孔屏+三星4nm芯片,售价或5999起
- 36氪5G创新日报0112|福建省首个“5G+VR”英模会客厅正式上线;齐鲁医院健康管理中心“5G+ 5g
- 物联网|据说,物联网也可以称之为“一张想想的网络”,物联网世界是梦
- 微信上线“语音暂停”功能