博雯 明敏 发自 凹非寺
量子位 报道 | 公众号 QbitAI
要致富先修路。
在面向智能时代的转型中,武汉深谙此理。
这不,多模态人工智能产业联盟,为此而来。
中科院自动化研究所牵头,华为、武汉人工智能研究院提供技术支持。
再看其他联盟成员:武汉大学、华中科技大学、中移系统集成、爱奇艺、新华社技术局……都是产学研各界耳熟能详的名字。
它们聚集在武汉,搞了这个“大合体”的目的也很简单:
依靠和联盟成员的合作,要把多模态人工智能产业落地推进到底。
这是一个怎样的组织?先从关键词解题。
“模态”。这是一个认知领域的概念,指某种信息的来源或形式,或者“某件事情发生、被感知到的方式”。
人的触觉、听觉、视觉、嗅觉,作为信息媒介的语音、视频、图像、文字等都可以被称之为是一种模态。
“多模态”一词则更多出现在计算机科学领域:当一个研究问题或数据集包含两种及其以上的模态数据类型时,它就被描述为多模态(Multimodality)。
文章插图
而通过多模态进行交互和学习,一度被称为是“最接近类人脑智能的方式”。
究其原因,还是人脑的感知和认知过程,本质也是一个多种感官信息融合处理的过程。
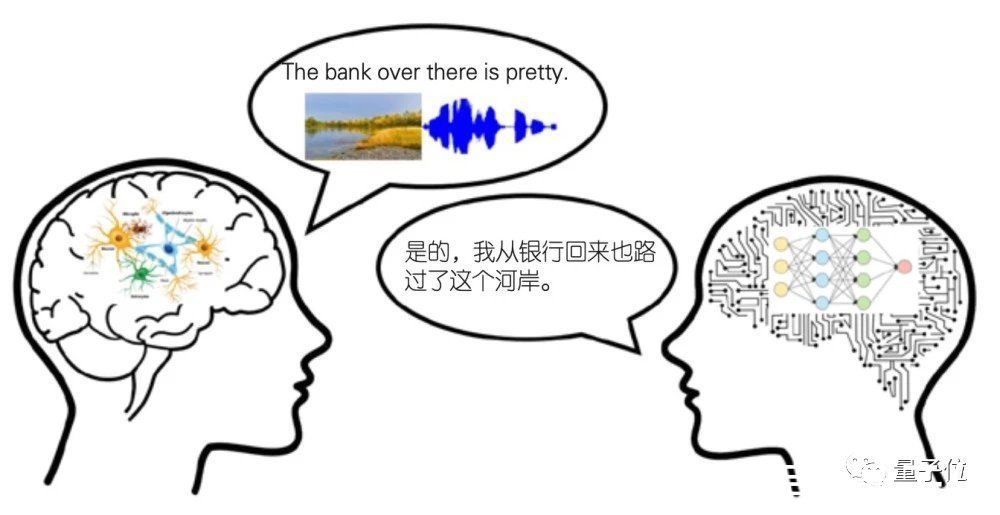
比如,人可以同时利用视觉和听觉信息理解说话人的情感:
文章插图
因此,人工智能领域近几年的一个热门方向,就是学习不同模态信息之间的关联,处理和理解多模态信息。
并且,这些技术已经应用在了我们生活中的各个方面。
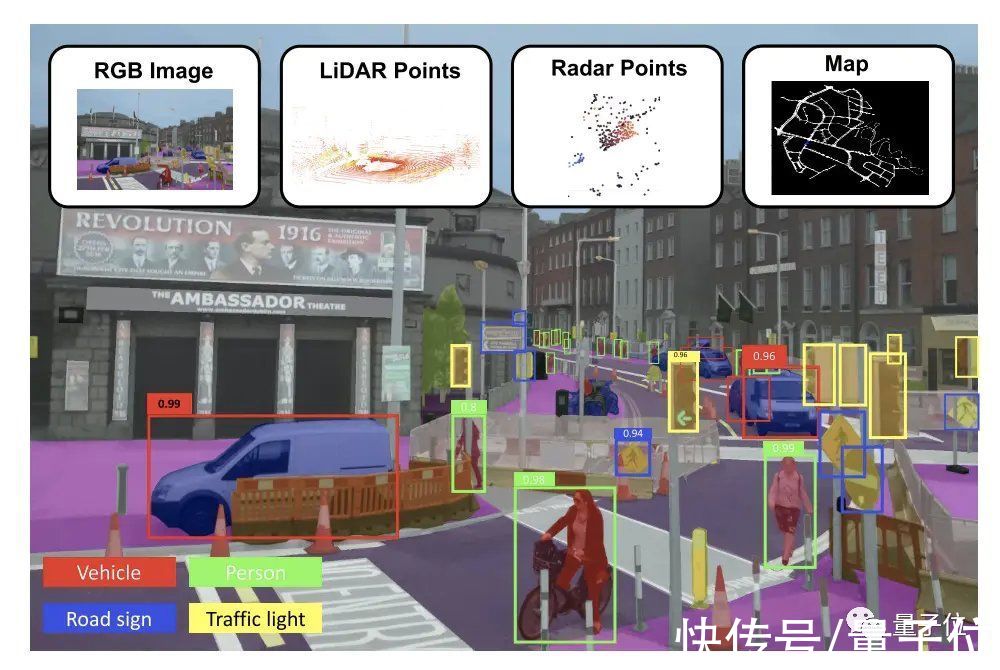
比如大家都熟知的自动驾驶技术,就是基于视觉摄像头、激光雷达、超声传感、地图等多种模态的传感器实现的:
文章插图
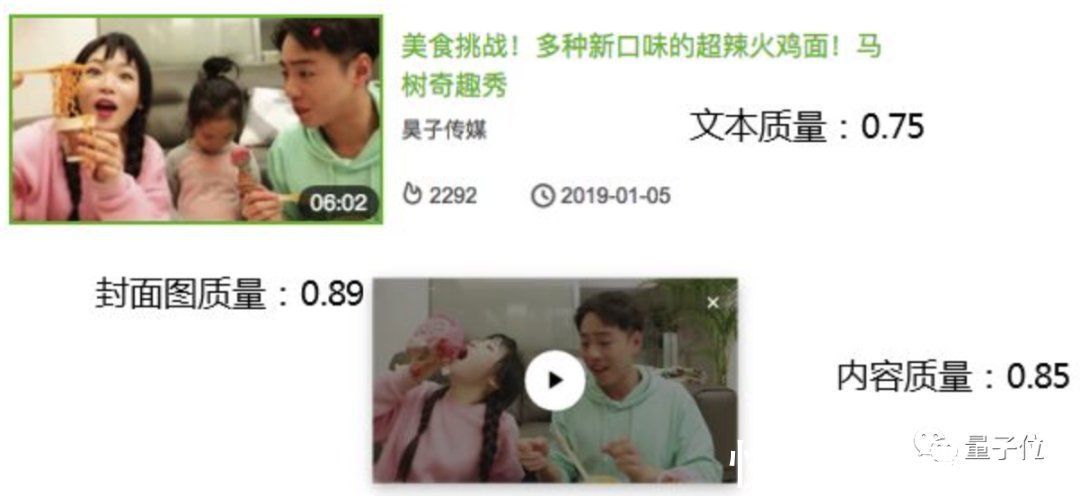
还有一些视频网站的智能化推荐,也是通过分析视频封面、视频抽帧和文本几个模态的信息对视频质量进行评估:
文章插图
此外,通过语音识别和视觉感知理解语义的智能音箱、结合产品图像和语义属性进行推荐的智能客服、融合人脸声音虹膜等多种信息进行身份识别的安全系统,都是多模态技术的体现。
所以多模态人工智能产业联盟会聚集各行各业的成员,也就再自然不过。
牵头的中科院自动化研究所,国内最早开展类脑智能研究的国立研究机构,拥有3个国家级重点平台和数十个重点实验室及研究中心。
今年9月份,中科院自动化研究所在华为全联接大会发布了全球首个三模态大模型紫东.太初。这一模型拥有千亿级别的参数,能够跨越视觉-文本-语音三种模态进行统一编码。
在今年的两项AI顶会,ACM Multimedia和ICCV的视频语义理解与视频描述赛道中,“紫东.太初”拿下两项冠军,在跨模态理解与生成性能上都展现出了目前业界的最高水准。

文章插图
多模态联盟将基于紫东.太初,孵化更多行业应用,并进一步探索通用人工智能新路径。
联盟的理事长由中科院自动化研究所所长徐波担任。
另外三位副理事长,也是多模态领域的重要玩家。
他们分别来自华为、爱奇艺和武汉昇腾人工智能生态创新中心。
其中,昇腾AI平台包括Atlas系列硬件、异构计算架构CANN、全场景AI框架昇思MindSpore、昇腾应用使能MindX以及AI应用使能ModelArts等,为开发者和企业高效使用AI能力,创新场景化AI应用,加速千行百业智能升级,可以说是目前业界极其领先的全场景AI平台。
- 城市|新华社:武汉抢抓数字经济新“基”遇
- 零售业|阿里再生独角兽,估值百亿美元,马云果然有远见
- 85英寸双120Hz高刷屏,价格低至7777元,优质电视果然不会被冷落
- 大脑|(稳健前行开新局)武汉:抢抓数字经济新“基”遇
- 程序员|阿里再生独角兽,估值百亿美元,马云果然有远见
- 马云|突然现身!马云果然没食言!
- 武汉市自然资源和规划局2021年十大亮点工作
- 武汉|中兴通讯武汉研发中心项目落户光谷
- 苹果|李彦宏果然不简单,7年前预判耗资数百亿研发,今成绩堪比华为
- 魅蓝|魅蓝10外观曝光,果然是基础手机,网友:拿什么吸引魅友回归?