所有的数据可视化基本上都是由BI开发的一个个报表堆砌的,所以BI也是数据的重要参与者。由BI侧导致的数据波动大多数出现在口径不一致的问题上。
这里可能有很多产品和运营的小伙伴深有同感,自己公司的BI经常会在不同时间点给出统一口径下的两份不同数据。
这里我为广大的BI同学们正名一下,作为BI,数据的准确性是我们的红线,给出准确的数据是我们的义务。但是往往随着公司业务规模的扩大,之前的底层数据架构开始不堪重负。再加上人员的流动,很多历史遗留问题开始凸显。这时,大多数的公司还处在追求业务扩张的阶段,不会花时间和资源来处理数据底层架构的问题,毕竟花时间又看不出明确产出。
这个问题的破局只有自上而下,具体在这里不细说。
最后一个生产关系是数据的加工者,即开发侧的数据开发、数仓。这是最容易忽视却是出问题频率较高的部分。
这里要简单说下我们的数据生产加工过程。用户生产的行为、属性等数据并不是直接生成的可视化报表,需要经过ETL清洗、数据入库、再到数据处理,最后成为可视化看板。
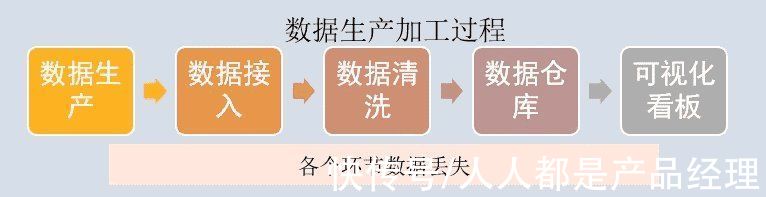
文章插图
而在上述的每个环节中,都可能会造成数据丢失的问题。常出现的问题有对接的服务器漏采集数据,传输数据的服务器之间未添加白名单导致数据丢失等。
很多时候查到这里确认是这个问题后,我们会恍然大悟。
三、数据异常归因经过前面两步:数据异常检测、数据异常定位,我们基本上定位到了数据波动的因素,那究竟是不是这个因素导致了我们的波动?
这里举个例子方便大家理解我们为什么还要做归因这个步骤。比如五年级的小明在之前几次月考中数学都在95分左右,但期中考试数学只考了80分,小明妈妈非常不满意,认为是小明最近一直在玩手游导致的成绩下降。小明很委屈,他觉得这次是题目太难了。
妈妈为了证明是手游这个因素影响了小明的成绩,从期中考试结束后到期末考试期间,严格禁止小明玩手机。结果小明期末考试考了95,达到平时的成绩,小明妈妈就更坚定了是手游影响了小明的学习。
这里举的例子对应到业务中,也就是说在数据异常定位之后,我们还要证明确实是这个因素的变动导致了结果数据的变动。
在这个环节我们都是采用AB实验的思想,比如我们定位到了是新增用户变多导致了我们整体次日留存的下降。那我们就可以保证其他因素不动,只是剔除新用户,再取一下次日留存的数据,看看数据是否依然波动。
四、总结还记得我们一开始的问题吗?
如果XX指标发生了波动(上升或下降),需要你去定位原因,你的分析思路是什么?
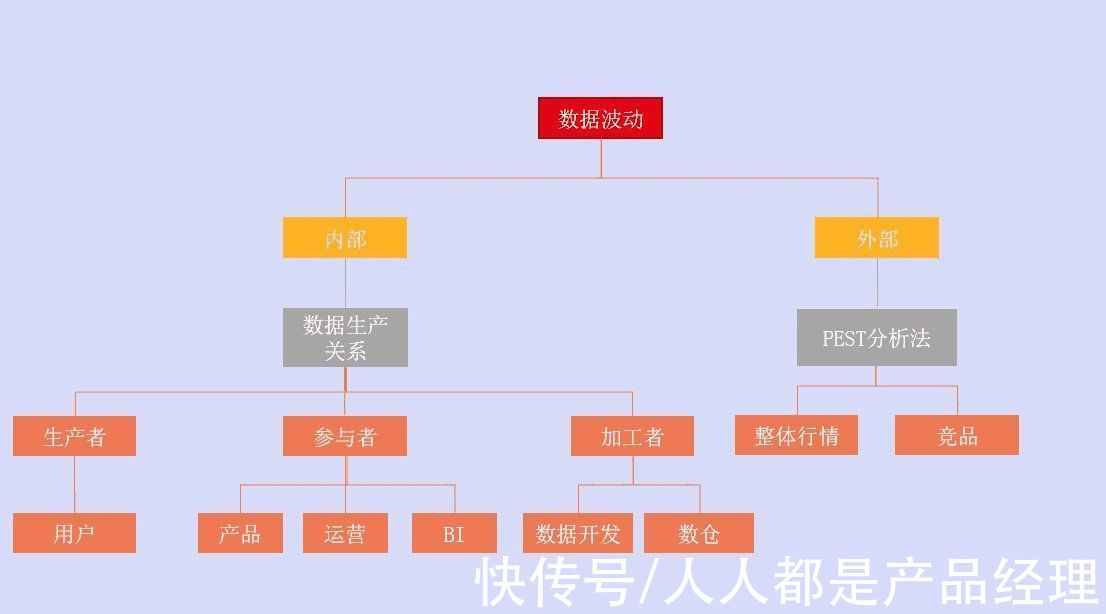
文章插图
通过我们前面的讲解,我们会这样回答:
- 通过数据异常检测确认业务所说的波动是否属于异常波动;
- 根据外部因素和内部因素分别进行排查;
- 用AB实验的思想进行数据异常归因。
微信公众号:董点数据。分享产品、运营、数据思维。
本文由 @董点数据 原创发布于人人都是产品经理。未经许可,禁止转载。
本文为人人都是产品经理《原创激励计划》出品。
【 数据|数据出现波动不要慌,手把手教你搭建数据异常监控体系】题图来自 Pexels,基于CC0协议
- text|《2021大数据产业年度创新技术突破》榜重磅发布丨金猿奖
- 酷睿处理器|关键数据出炉,京东比阿里差远了
- 苹果|苹果最巅峰产品就是8,之后的产品,多少都有出现问题
- 财智干货|数智化发展任重道远,财务中台提升数据服务价值 | 大数据
- 央媒表态后,联想关键数据出炉,柳传志这回要扳回一局?
- 数据库|OPPO悄悄上新机,骁龙8核+5000mAh电池,256G仅售1599元
- Windows|如果美国让微软断供中国windows系统,不会出现什么影响
- 新车就出现故障|路虎新车开两个月频繁出现故障灯,4s店:会给予补偿
- 数据仓库|红米真我moto三款骁龙870手机对比:2000元以内,谁更值得买?
- 中文|爱数智慧CEO张晴晴:基于”情感“的人机交互,要从底层数据开始