为更高效、更经济的实现针对神经网络的训练,特斯拉打造了Dojo超级计算机,并在上周五的AI Day上做了首秀。
彼时,AI Day演讲已经进行到最后一个环节,Dojo超算项目负责人Ganesh Venkataramana正站在舞台上滔滔不绝。如何在人工智能训练芯片D1的基础上,构建Dojo超算系统的基本单元——一种集成了25个D1芯片的训练模块(Training Tile)?
特斯拉找到的一个关键答案是用台积电的InFO_SoW整合扇出技术,这是一种芯片先进封装技术。当Ganesh说着“这是真的”,并把一块做好的训练模块展示给台下观众时,他理所应当地得到了掌声。

文章插图
但有趣的事情不止于此。据公开信息,上一个使用了这个先进封装技术的公司是美国创企Cerebras。换言之,特斯拉是已知使用到该技术的第一家汽车公司(虽然现在的特斯拉已经越来越像是一家人工智能公司了)。
Dante Tech曾判断超算可能会成为自动驾驶下一个发展阶段中的核心生产力工具,而新的需求同时也推动了相关先进技术的应用。汽车产业产业链的价值重构,正与其他的产业变革发生着奇妙的联动。
Dojo超算拆解
我们从特斯拉那里拿到的资料中,对于Dojo超算有一个有趣的形容——“工程学的创举”。这意味着Dojo超算上所做的创新更多属于应用过程中的创新,对于这个说法,特斯拉应该是认的。这就类似于大家手里都有一本字典,学霸用起来效果更好,但就字典本身而言倒没什么特别奇怪的。
回到Dojo超算,特斯拉的具体目标是要做到:达到最佳的AI训练性能、能够支撑更大和更复杂的神经网络模型、并能够优化能耗成本。
而要实现目标,特斯拉认为最紧要的事是克服带宽和延迟的问题。因为对于超算而言,算力扩展是“小事”,算力可以通过堆芯片堆上去,解决数据传输的带宽和延迟瓶颈才是真正的难题。
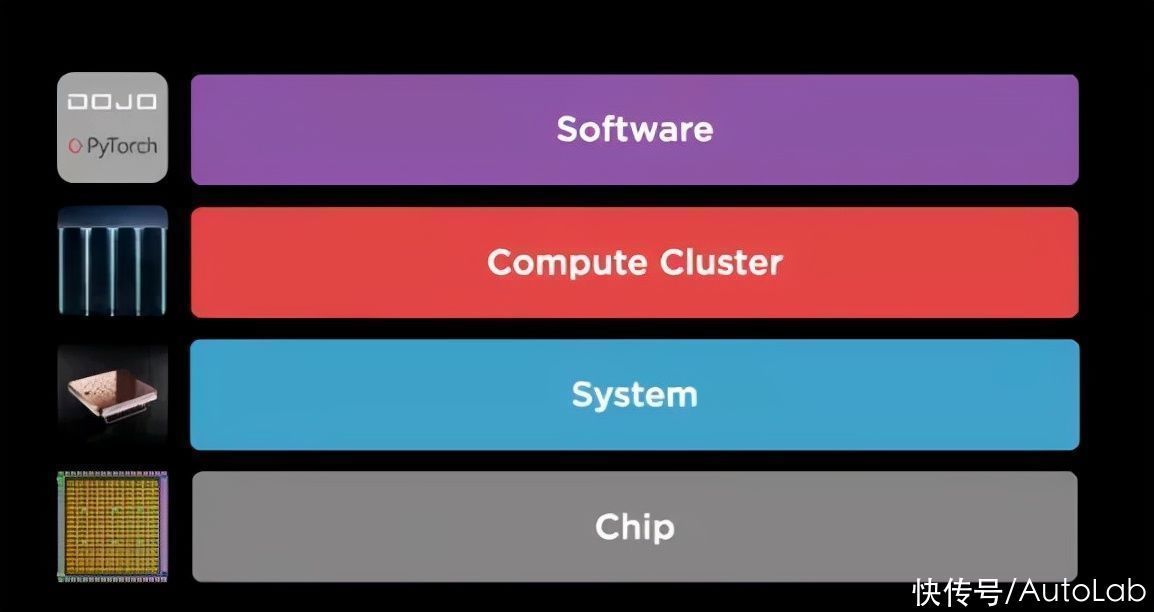
如何解决这个难题?特斯拉的解题方法是在硬件(芯片、系统、计算集群)和软件层面上同时入手,做优化。
文章插图
关于Dojo超算的现有文章中提到软件层的较少。但软件层实际上很关键,因为并不是所有的工作都需要依靠巨大的计算集群来完成。在软件层面上,特斯拉开发了一款虚拟化工具DPU(Dojo Processing Unit)。
一个DPU可以由一个或者多个D1芯片构成,同时搭配接口处理器和主机,最重要的是它可以根据运行在上面的算法的大小进行扩展或者缩小,具有相当的灵活性。
在整个软件层面,特斯拉构建了一套由PyTorch(一个深度学习框架,特斯拉对其进行了扩展)、编译器、驱动程序、分析器和调试器共同构成的软件栈。
Dojo超算的硬件设计,从内至外可以分为芯片、系统、计算集群三个层级。
芯片上承载了最小的计算元素,这里被称为「训练节点」。训练节点内置一个4线程的超标量CPU、1.25MB SRAM缓存、低延迟的数据交换结构、SIMD单元、多个8X8乘法矩阵等。同时,每个节点内部和四周都布满了用于数据传输的线路。
每个训练节点的性能表现如下:算力在BF16/CFP8数据格式下,为1024GFLOPS(每秒执行浮点运算次数超过了1万亿次),在精度更高的FP32格式下,浮点运算性能达到64GFLOS(每秒执行浮点运算次数超过640亿次)。
354个这样的训练节点连接到一起,构成计算阵列(compute array)。演示为正方形的计算阵列,再配合围绕在四条边上的高带宽结构(可提供4TB/s的片外带宽),便在逻辑上构成了一个D1芯片——一个由特斯拉研发的人工智能训练芯片。
- 自动驾驶|华为首秀自动驾驶,王兴:特斯拉遇到技术与忽悠能力相当的对手了
- 热泵低温被爆低温“歇菜”!特斯拉OTA解决:寒冷地区-15℃仍可能失效
- 埃隆马斯克|一句话暴涨20%!马斯克称将允许新加密货币购买特斯拉周边
- 19岁黑客控制了25辆特斯拉,能远程遥控车辆完成多种指令
- 特斯拉|生命安全至上!复旦教授称不要尝试L2级别以上自动驾驶
- l2|吹半天,特斯拉自动驾驶只达到了L2级?
- 特斯拉|特斯拉350元哨子暴力拆解:切割干废几个“飞轮”
- 黑客|最担心的事还是发生了 19岁黑客远程破解逾25台特斯拉
- 印度|富士康又停工,特斯拉落荒而逃,印度靠一个懒字,吓退美国资本
- 特斯拉|专注提升耳机体验 Android 13首个重大功能揭晓