数据留痕|数据留痕的两种使用场景:电子文档修改和流程留痕
编辑导语:数据在变动之后有可能留下痕迹,此时这类痕迹就称为“数据留痕”。而数据留痕在一定程度上可以帮助业务人员寻找易混淆的信息,寻找数据可能出错的起点。本篇文章里,作者就对数据留痕的定义和场景做了解读,一起来看一下。

文章插图
一、背景医学科研中,原始数据经过解析,完成数据的首次填充。然后经过多轮校验和修改,最终形成高准确度的数据。但是数据演进的过程越长,出现错误的概率也就越大。使用错误数据进行科研,科研结果的准确性就会受到影响。
当数据出现问题时,由于没有记录数据演进过程,所以无法了解数据是“何人何时修改了何种信息”,缺少了寻找错误的起点。
例如,数据库中记录患者李明的“就诊年龄=61岁”,但是医生通过其他资料查询,认为就诊年龄应该是59岁。由于没有记录中间演进过程,所以不知道是什么原因产生了这种差异。也不知道是谁因为什么修改的这个数据。
其实,数据的演进过程是这样的。其中“61岁”是通过身份证号和当时的就诊日期自动计算出来的。后面经过数据核查,“李明的身份证年龄比实际年龄小2岁”,于是修改李明的“就诊年龄=59岁”。
上述案例中,“就诊年龄=61岁”,“就诊年龄=59岁”是数据的痕迹。“由身份证号和就诊日期计算所得”“身份证年龄比实际年龄小2岁”是数据修改的原因。
由于缺乏数据修改记录和数据修改原因,这种情况下可能会产生两个后果。
- 医生手动将61岁修改为59岁。原本正确的数据,被修改错误。如果筛选年龄介于18-60的患者。该患者就会被误选进入研究样本中,对研究结果产生干扰。
- 医生无法确定哪个数据准确,为了保证数据的准确性,则不适用该数据。那么研究的样本中就会少一例。当可供研究的样本数量较少时,减少一个研究样本就少了一份可用数据。
这就是我们今天讨论的话题,数据留痕。
二、数据留痕指的是记录数据的每一次变动,让每一次数据变化都留下痕迹。一条留痕记录包括两部分内容,变动信息和变动原因。
变动信息,指的是用户在提交数据时,提交后的数据相较于提交前上一次数据,发生变动的地方。主要数据有变动变量、变动前的结果(原值)、变动后结果(现值)、变动时间、修改人。变动信息具备事实性,能够准确的反应数据发生变动时的场景。
变动原因,指的是产生本次数据修改的原因。该部分信息是由用户手动填写完成,在数据提交时由系统记录的。数据的信息量大,价值高。主观性较强,准确性无法保证。
举例:
文章插图
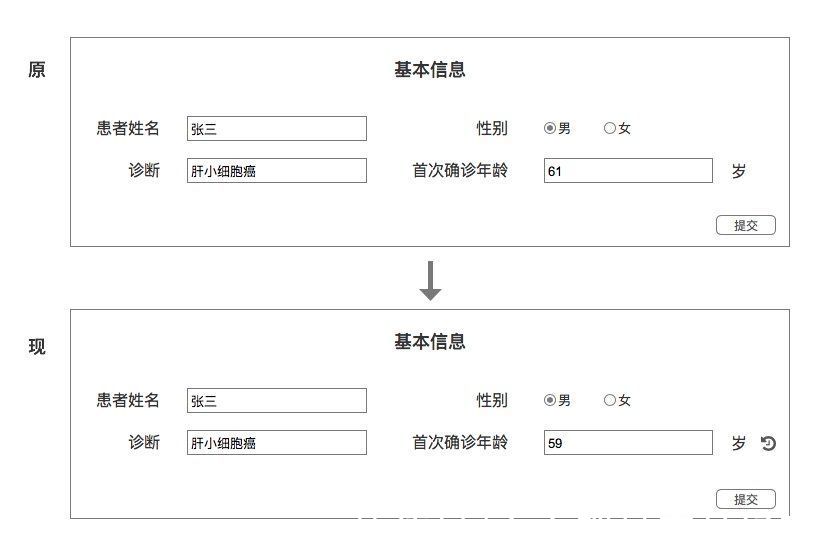
在表单“基本信息”中,点击提交按钮,“首次就诊年龄“从原值“61岁”变更为现值“59岁”。同时,系统产生一条留痕记录。

文章插图
留痕记录中,变动信息:
① 变动时间:2021-2-2 19:04,记录执行提交任务的时刻。
② 修改人:张三医生,记录执行数据提交任务的人。
③ 变动变量:就诊年龄,记录修改的变量。
④ 原值:61岁,记录变量修改前的结果。
⑤现值:59岁,记录变量修改后的结果。
变动原因:
⑥变动原因:李明的身份证年龄比实际年龄大2岁,61岁是根据身份证号计算出来。
- 美国|因果循环!韩国企业受限于美国的压力,中国92亿收购计划被叫停!
- 小米科技|U盘一样大的移动固态你见过吗?奥睿科IV300固态硬盘带来全新体验
- 微信|中介都在自己的微信名前加A,“专家”:这个A值得好好研究
- it芯片|荣耀50 Pro跌到2000档价位,幸福的感觉
- 电子商务|Web前端培训:创建用户友好的移动响应式网页设计的11个独特技巧
- 豪车|PCIe 6.0将达到带宽64 GT/s?
- 即时零售|行业观察|从美团歪马送酒,看崛起的即时零售
- 支付宝|支付宝集五福首次增设无障碍小店卡!县里的小店也能上福卡了
- 等一个小天鹅的消息是什么梗 等一个小天鹅的消息是什么意思
- Redmi|临近春节Redmi Note 11系列销量越来越高了!MIX 4上的120W它也有