
文章图片
文章图片

文章图片
文章图片

文章图片
文章图片
文章图片
文章图片
文章图片
文章图片

文章图片

文章图片
文章图片
业务背景 在实际业务使用中 , 需要经常实时做一些数据分析 , 包括实时PV和UV展示 , 实时销售数据 , 实时店铺UV以及实时推荐系统等 , 基于此类需求 , Confluent+实时计算Flink版是一个高效的方案 。
Confluent是基于Apache Kafka提供的企业级全托管流数据服务 , 由 Apache Kafka 的原始创建者构建 , 通过企业级功能扩展了 Kafka 的优势 , 同时消除了 Kafka管理或监控的负担 。
实时计算Flink版是阿里云基于 Apache Flink 构建的企业级实时大数据计算商业产品 。 实时计算 Flink 由 Apache Flink 创始团队官方出品 , 拥有全球统一商业化品牌 , 提供全系列产品矩阵 , 完全兼容开源 Flink API , 并充分基于强大的阿里云平台提供云原生的 Flink 商业增值能力 。
一、准备工作-创建Confluent集群和实时计算Flink版集群
【apache|基于 Confluent+Flink 的实时数据分析最佳实践】
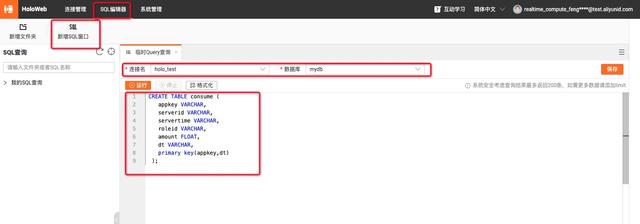
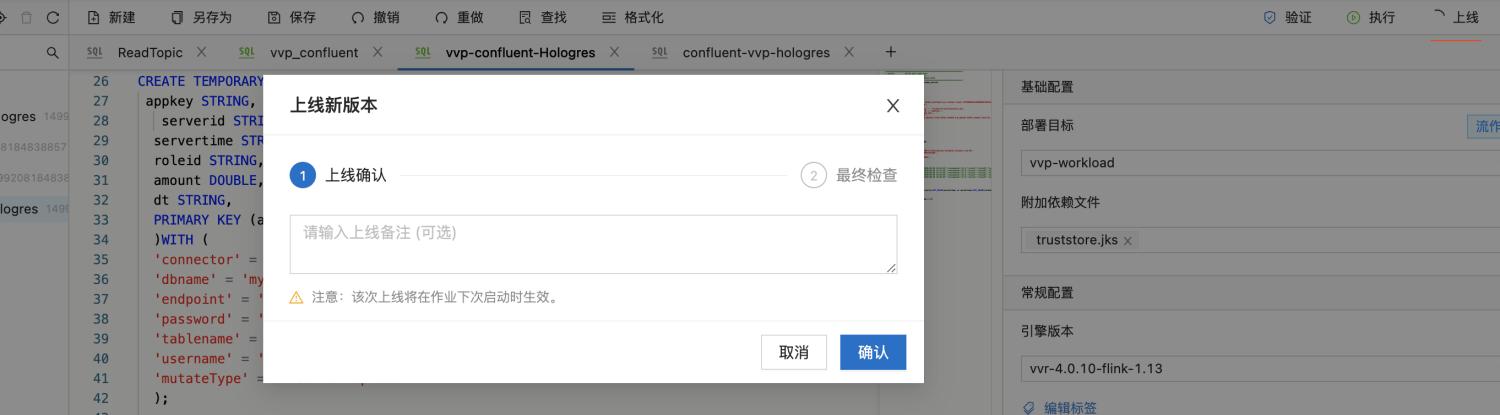
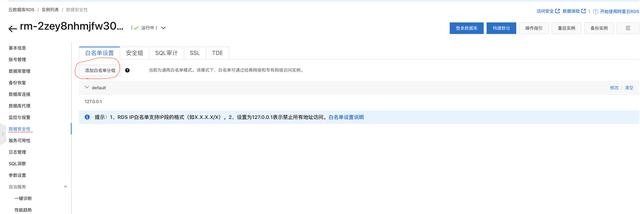
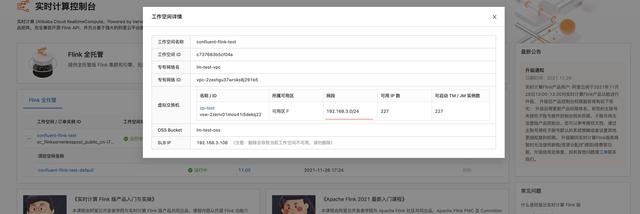
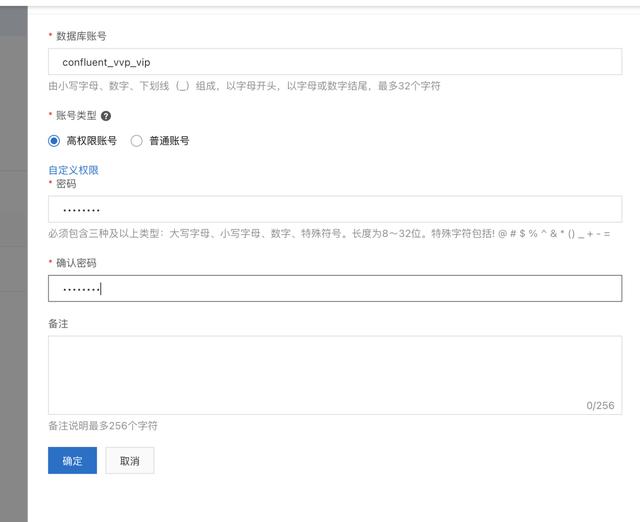
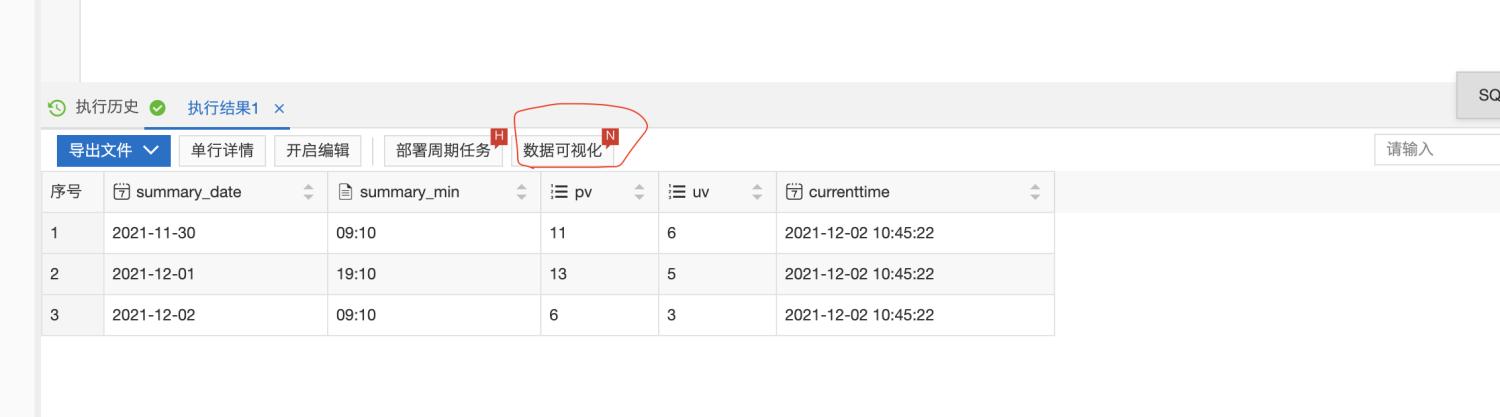
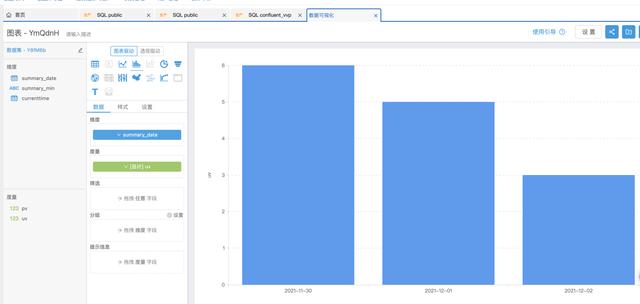
登录Confluent管理控制台 , 创建Confluent集群 , 创建步骤参考 Confluent集群开通 登录实时计算Flink版管理控制台 , 创建vvp集群 。 请注意 , 创建vvp集群选择的vpc跟confluent集群的region和vpc使用同一个 , 这样可以在vvp内部访问confluent的内部域名 。二、最佳实践-实时统计玩家充值金额-Confluent+实时计算Flink+Hologres 2.1 新建Confluent消息队列 在confluent集群列表页 , 登录control center 在左侧选中Topics , 点击Add a topic按钮 , 创建一个名为confluent-vvp-test的topic , 将partition设置为3 2.2 配置结果表 Hologres 进入Hologres控制台 , 点击Hologres实例 , 在DB管理中新增数据库`mydb` 登录Hologres数据库 , 新建SQL Hologres中创建结果表 SQL语句 --用户累计消费结果表 CREATE TABLE consume ( appkey VARCHAR serverid VARCHAR servertime VARCHAR roleid VARCHAR amount FLOAT dt VARCHAR primary key(appkeydt) ); 2.3 创建实时计算vvp作业 首先登录vvp控制台 , 选择集群所在region , 点击控制台 , 进入开发界面 点击作业开发Tab , 点击新建文件 , 文件名称:confluent-vvp-hologres , 文件类型选择:流作业/SQL 在输入框写入以下代码: create TEMPORARY table kafka_game_consume_source( appkey STRING servertime STRING consumenum DOUBLE roleid STRING serverid STRING ) with ( 'connector' = 'kafka' 'topic' = 'game_consume_log' 'properties.bootstrap.servers' = 'kafka.confluent.svc.cluster.local.xxx:9071[xxx可以找开发同学查看
- 评测|华为推出基于华为云的云桌面服务正式商用
- 传感器|基于ESP32的多传感器无线模组,TDKSmartBug物联网方案,飞睿科技乐鑫代理
- 摩尔线程| 摩尔线程发布基于MUSA统一系统架构的第一代桌面级显卡MTT S60
- VR教育|XR Immersive Tech与VictoryXR达成合作,基于LBE VR市场推广VR教育
- 元宇宙|可捕捉情绪状态,Nemesysco推出基于AI的元宇宙语音分析工具
- 隔离|外卖本质:基于数据的餐饮零售
- 自动驾驶|为什么说“万物基于MIUI”?
- |国内首台基于HDMI 2.1的8K信号发生器发布
- 银河系|天文学家基于LAMOST数据揭示银河系早期形成和演化历史
- 李超等-Geophysics:基于不可逆偏移滤波的波场分离方法