文章图片
文章图片
急需精细化内容运营的淘宝订阅 淘宝订阅是基于C-B关系的用户/商家双私域产品 , 用户侧与推荐-猜你喜欢互补 , 构建订阅-我的喜欢心智 。 商家侧与商家深度联动 , 结构化 , 自动化引入优质供给 , 帮助商家更好地运营粉丝会员 。
初期构建了从商家后台内容发布 , 到算法分发推荐 , 再到前台消费和数据回收的完整链路;后期为了精细化运营 , 提升内容推荐体验 , 开始探索内容特征 , 搭建内容特征圈选系统 。
1、内容在推荐分发时需要使用特征
优质内容圈选 :在手淘订阅前台进行内容分发 , 支持多种维度的特征筛选方式 。低质内容过滤:涉黄涉政和无意义内容 , 通过特征筛选来进行过滤 。2、内容运营时需要使用特征圈选
核心内容投放展示:运营将挑选一批核心深度运营内容进行前台投放 , 通过圈选系统 , 按照不同的维度进行筛选 , 得到的内容用于前台的内容聚合页面 大促内容氛围加强:运营圈选得到一批活动内容 , 前台透出时会对其进行大促氛围加强 合作商家流量倾斜:通过圈选系统 , 圈出一批核心合作商家的内容 , 在手淘前台内容展示时进行流量倾斜 。 订阅内容特征圈选系统引擎选型 内容圈选是对现有内容的的一个筛选操作 , 圈选内容指标维度多 , 数据量大 , 对数据预览也有一定要求 , 因此需要整体设计一个方案 , 来使得圈选内容更加精准 。 另外 , 技术上也需要考虑到未来的扩展性 , 使得后续增加数据指标筛选更加方便 。
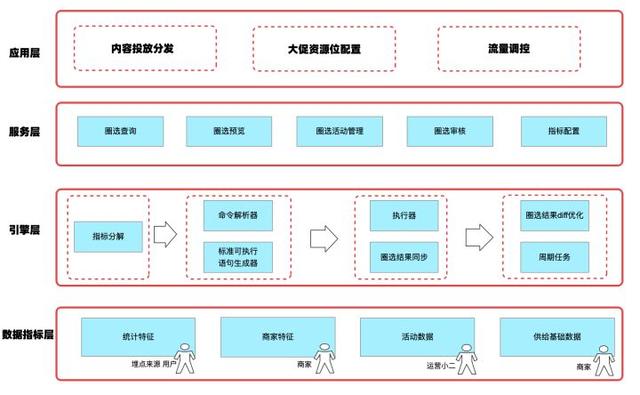
当前订阅圈选系统的架构设计 下面是内容特征生成和订阅圈选系统的设计方案 。
【喜马拉雅|Hologres 共享集群助力淘宝订阅极致精细化运营】
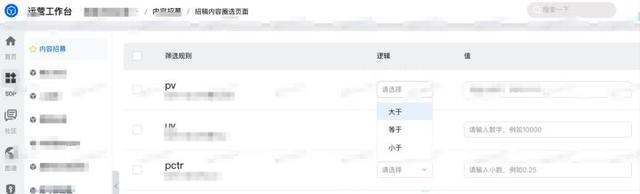
将圈选过程抽象为内容id+关联id+多维度指标筛选 , 得到筛选后的目标内容id的过程; 将圈选操作作为一个包含一批内容的活动实例的创建过程; 将可圈选信息配置化成筛选项schema; 将实际过滤条件值作为筛选项value 。因此 , 就可以将问题转变为基于筛选项schema和筛选项value , 按不同指标过滤 , 进行数据查询的操作 。引擎选型核心诉求:灵活性高性能 现有圈选系统已经支持了配置化 , 可以自定义数据源和指标进行圈选 。 圈选过程中 , 多个筛选项翻译成可执行查询语句的过程就是圈选引擎最核心的部分 。 筛选引擎需要对不同的筛选项映射到不同的表中的字段 , 生成可执行语句 , 再在筛选引擎中进行执行得到筛选结果 。 基于业务场景 , 我们总结出对筛选引擎的核心诉求如下: 接入简单 , 降低筛选可执行语句翻译的复杂度 性能和稳定性保障 , 圈选的逻辑跟随运营策略变化 , 需要支持复杂查询快速响应 。支持多变的特征字段添加 , 具有一定的灵活性 。通过在阿里集团内外的大量调研 , 并最终在几款产品之间做了详细的对比 , 具体如下: 方案对比 MaxCompute Hologres共享集群 灵活性 一般可多表关联条件查询 , 需指定表空间 高可聚合到同一空间多表关联条件查询 成本 低 中 , 无需数据导入导出就能直接查询 查询速度 一般单次查询15s以上 亿数据量级 , 单次查询秒级 通过Hologres集群搭建的订阅系统 通过调研和测试 , 最终选择了Hologres集群作为订阅系统的计算引擎 。 下面将会介绍订阅系统基于Hologres集群的最佳实践 。Hologres集群:更少的数据移动+更快的查询 1、使用成本低 快速接入: Hologres共享集群只需建立实例快速使用 , 可以方便业务快速入门 , 基本满足了大部分使用场景 。 当业务发展有需要的时候 , 可以再申请独立集群并迁移 , 这一点在集团众多引擎中是比较友好的 。 订阅业务也是在初期基于公共集群搭建 , 后期逐步开始使用独立集群 。无缝开发:Hologres所支持的SQL查询语法和常见的SQL查询基本一致 , 基本无缝使用 。 可视化界面支持一键同步表结构功能 , 尤其适合表结构经常变化的同学 。减少数据移动:Hologres天然支持通过外表方式读取存储在MaxCompute多个project的数据 , 这样就可以聚合来自不同project的离线数据 , 降低了查询的复杂度 , 无需数据导入导出就能直接查询 , 也降低了存储成本 。2、查询效率高 相比于MaxCompute的查询 , 性能提升很高 。 经过多次测试:数据量亿级别 , 外表查询复杂语句(包含多表JOIN)耗时约为8-9秒;外表单表筛选查询耗时在2秒左右 。 适合用于离线/准实时查询场景 。 内表查询约为60ms , 可用于在线查询 。通过支持 UDF/表达式下推 , 来实现用户自定义的UDF计算;将表达式下推可以减少无用的数据传输带来的开销 , 进一步提升性能 。通过Hologres搭建订阅系统最佳实践 通过Hologres共享集群搭建的订阅圈选系统流程如下图所示: 运营只需要在后台圈选页面勾选筛选项和填写筛选值 , 圈选系统将会自动生成Hologres SQL语句(如下示例)并在Hologres中执行获取数据 , 最终将数据返回到前端 , 并进行前台投放 。 运营再根据投放效果不断优化圈选方案 , 提升圈选效果 , 达到更加精细化运营的目的 。整个过程 , 不需要数据在各个系统之间的导入导出 , 仅通过页面点击的方式 , 就能转化为SQL进行计算 。 同时可以根据业务逻辑调整圈选内容 , 复杂的SQL也能快速高效的计算出想要的圈选数据结果 , 节约获取数据的时间 。 使得整个链接变得非常的简单高效 。SELECT feed_idFROM qn_xxx_provider AS aWHERE a.xxx_pv30000AND a.xxx_pctr'0.1'AND a.last_publish_time= '2022-06-17 08:00:00'AND a.biz_xxx_code = '111'AND a.ds = MAX_PT('xxxxxx_table')AND CAST(a.owner_xxx_id AS VARCHAR) IN (SELECT b.domain_xxx_id FROM xxxxxxx_table AS b WHERE b.rule_type = 12 AND b.channel_xxx_id = 137 AND b.dataset_xx_id = xxxxx AND b.ds = MAX_PT('xxxxx_odps_channel') )and a.feed_id in (SELECT feed_id from xxxxx_submission_feed_hh where activity_id = 222 and approval_status=1 and ds = MAX_PT('xxxxx_submission_hh') and hh = '13'); 业务价值 通过Hologres共享集群搭建的淘宝订阅系统 , 支撑了1000+场运营圈选活动任务 , 支持了双11、618、新势力周等多场大促活动 , 支撑了订阅玩搭场景等的多个二级页面配置 , 简化了订阅系统的搭建 , 无需数据导入导出就能直接加速离线数据 , 降低了运营的上手成本 , 能让业务更加高效的专注于业务增长 。在未来 , 我们也将会持续使用Hologres来丰富订阅系统的功能 , 以此来保持业务的高速增长 , 我们希望圈选系统能够: 支持更实时的特征: Hologres内表性能更优越 , 将实时特征导入到Hologres内表中 , 支持实时特征的查询 降低调优GUC参数的使用 , 例如:set hg_foreign_table_max_partition_limit =128;(调整单次query访问外表分区数) ,期望可以更好的产品化能力解决 , 降低GUC参数的使用 。作者:杜仲舒 (花名:神天) 淘宝订阅开发 , 现主要负责淘宝订阅业务 , 主研内容特征理解 。原文链接:http://click.aliyun.com/m/1000347779/ 本文为阿里云原创内容 , 未经允许不得转载 。
- 据国家知识产权局官网显示|华为harmonyos专利曝光:增强屏幕共享方法
- 本文转自:中国网2022年6月29日|上海中建lyf虹桥共享公寓“云上”弄潮,惊喜开业!
- 本文转自:浙江日报浙江新闻客户端 记者 王凯艺 袁佳颖 共享联盟镇海站 董美巧“有了这个...|镇海:首条导盲公交线上路了
- 本文转自:沈阳晚报一种黑科技“智能头盔”在沈阳全新亮相目前沈阳路面上的共享电单车基本配备...|沈阳共享单车黑科技亮相
- 有照片!喜马拉雅山脉发现“雪人”踪迹,但是很多人不相信
- 微信 Windows 测试版 3.7.5.5 发布:群视频通话时可共享屏幕
- 喜马拉雅首推短剧,音频平台入局微短剧赛道
- 喜马拉雅山出现的“雪人”是何生物?目击者:智商高、攻击性强
- 喜马拉雅发现新物种!科学家发现“雪人”遗物,令人感到意外
- 是恶作剧还是新物种?喜马拉雅山出现的“雪人”,到底是什么?