文章图片
文章图片
文章图片
文章图片
文章图片
文章图片

\">一、背景简介在项目研发的过程中 , 对于数据存储能力的依赖无处不在 , 项目初期 , 相比系统层面的组件选型与框架设计 , 由于数据体量不大 , 在存储管理方面通常容易被轻视 , 当项目发展进入到中后期阶段 , 系统的复杂性很大程度来源于数据层面;
数据膨胀的时候 , 必然会放大细节 。
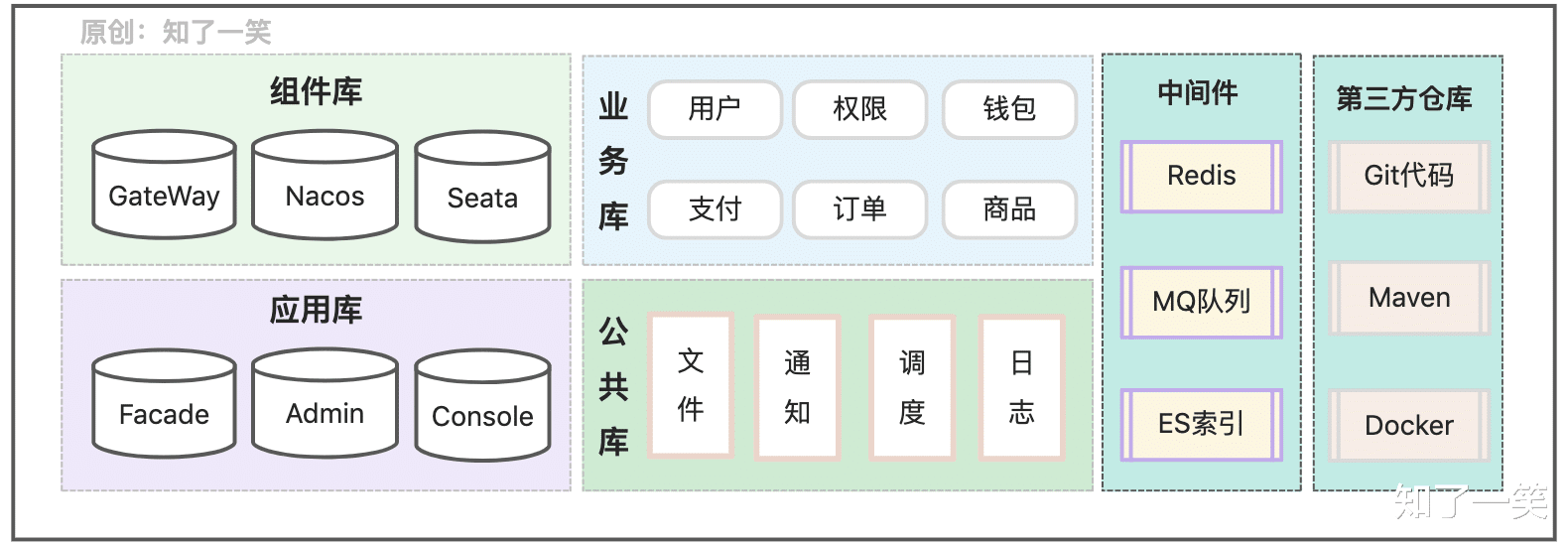
从常规的微服务架构体系来看 , 对于系统中的数据存储可以划分如下几个模块:组件库、应用库、业务库、公共库、中间件数据、第三方;不同的场景下对数据存储能力的要求和依赖程度也各不相同;
组件库:微服务架构下 , 诸多基础的框架组件都依赖数据的持久化存储 , 以此来确保服务能力的稳定可控 , 避免异常情况下的数据丢失问题;
应用库:作为系统中的应用层 , 需要对请求的动作有记录和识别能力 , 并且存储诸多拦截和过滤的规则信息 , 用来维护下层业务服务的安全稳定;
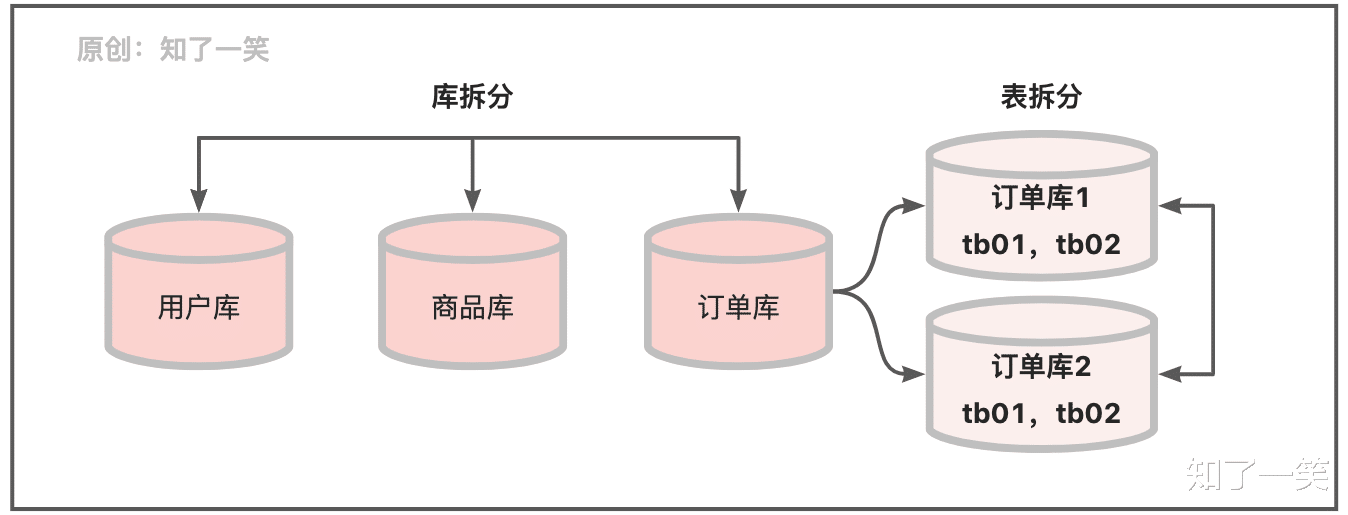
业务库:作为系统中最核心的数据资产 , 对业务数据的存储和管理有极高的要求 , 并且要对数据的变化有一定的评估能力 , 提前做好数据膨胀的情况下系统测试和拆分方案 , 保障业务的稳定和持续发展;
公共库:系统中大部分业务都可能会依赖的能力 , 对于公共库和与之相应的服务来说 , 其吞吐量和并发能力 , 要支撑所有依赖业务的同时并发;
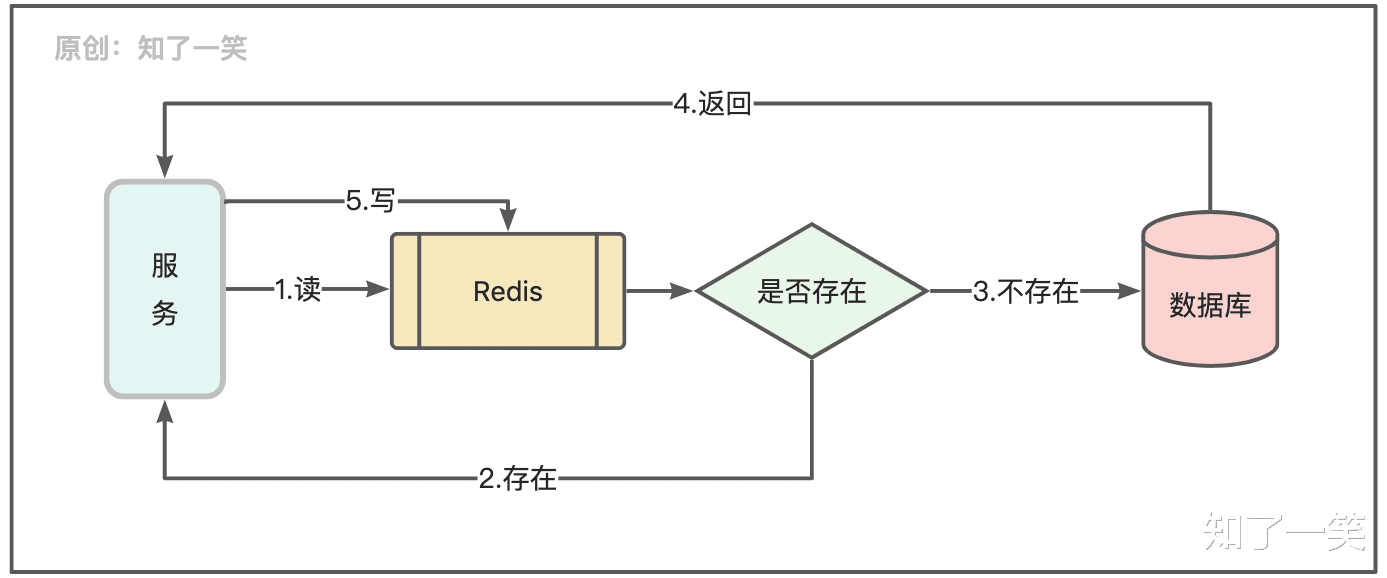
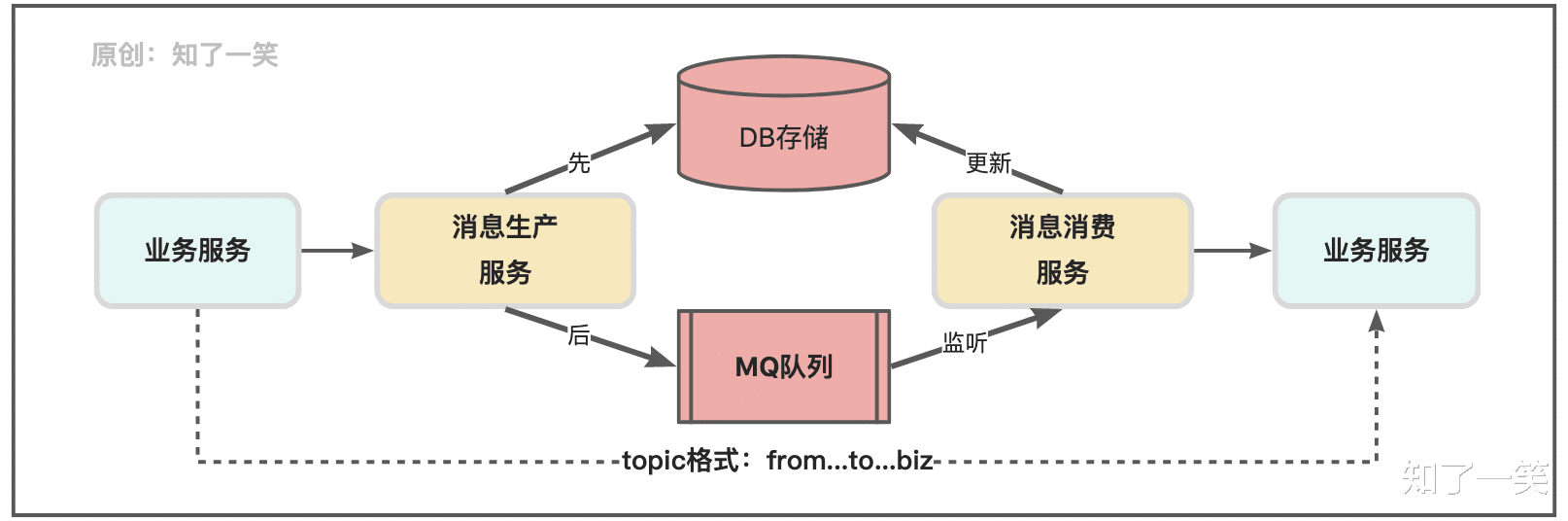
中间件:常见的中间件比如:缓存、消息队列、任务调度、搜索引擎等 , 都有数据存储的性质 , 只是在实现方式上会有差异;
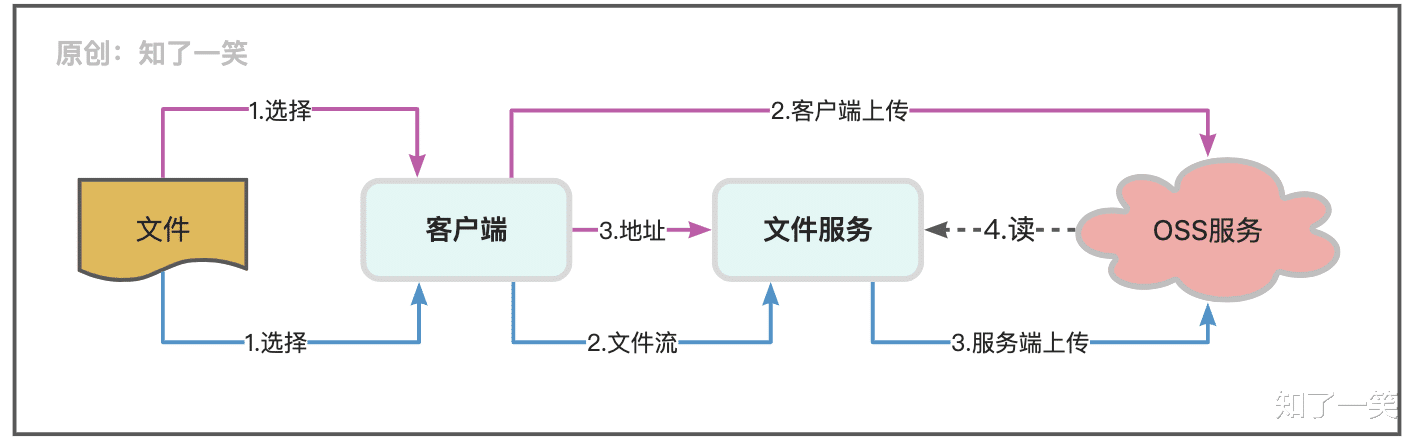
第三方:大部分系统都或多或少地依赖一些第三方仓库 , 比如Git代码仓库、Maven包仓库、Docker镜像仓库、行为埋点数据、OSS文件服务等;
二、框架组件微服务架构的常用组件中 , 例如GateWay路由网关、Nacos注册配置中心、Seata事务管理器等 , 都需要数据存储机制;
路由网关:通常在网关库中维护各个服务的路由地址和规则策略 , 以及黑白名单和流量管理等数据 , 虽然体量并不大 , 鉴于网关服务需要支撑流量的高并发 , 所以对数据的读性能有要求 , 尽量降低请求在网关层的耗时;
注册配置:统筹管理各个服务的配置数据 , 动态维护服务的注册状态 , 对存储的稳定性和数据安全有极高要求 , 要确保各个环境是隔离开的 , 并且不能暴露生产环境的配置信息;
事务管理:Seata组件提供高性能和易用的分布式事务管理能力 , 常规的事务调度过程需要依赖几张关键的记录表 , 通常需要进行分布式事务管理的接口 , 基本都是处理服务中的核心业务 , 既要保证稳定性也要支持高并发;
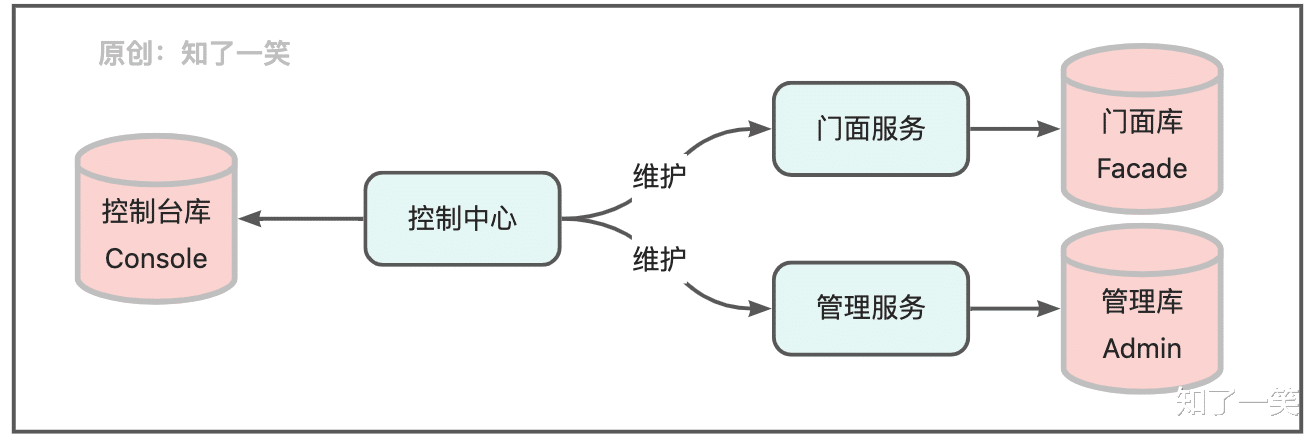
三、应用管理应用层相对处于系统的上层 , 比如常见的门面服务 , 管理服务 , 控制中心等 , 通常在相应的库中存储请求记录 , 特定的过滤和拦截策略 , 异常响应日志 , 页面的展示管理等;
- 华为鸿蒙系统|鸿蒙再进一步,谷歌紧跟着删代码,外媒:太晚了
- 华为鸿蒙系统|后置奥利奥相机模块 华为MatePad Pro11官宣 有望预装鸿蒙3.0
- 华为鸿蒙系统|鸿蒙3.0即将推送,你的机型可以升级吗?
- 华为鸿蒙系统|看看空调常见小故障,哪些是用户自己可以快速修复的
- 台电|旧电脑升级台电A810 512G固态硬盘,没想到系统迁移这么简单
- 2022~案例分享(二十一)~红外对射报警系统在某油库应用案例
- 2022~案例分享(二十)~红外对射在某码头防入侵报警系统应用案例
- 小米供应链发布最强按键手机:3.5寸超清屏+安卓12系统+116克!
- 本文转自:多彩贵州网多彩贵州网讯(本网记者 骆文文)近日|多彩博虹产品与华为鲲鹏平台、银河麒麟系统实现兼容互认
- 华为鸿蒙系统|外媒:砍单280亿颗芯片只是“前菜”,老美该担忧的是鸿蒙破圈!