FICCV 2021 | audi

文章插图
作者 | 张晨旭
编辑 | 王晔
本文是对发表于计算机视觉领域的顶级会议 ICCV 2021的论文“FACIAL: Synthesizing Dynamic Talking Face with Implicit Attribute Learning(具有隐式属性学习的动态谈话人脸视频生成)”的解读。
文章插图
作者:张晨旭(德克萨斯大学达拉斯分校);赵一凡(北京航空航天大学);黄毅飞(华东师范大学);曾鸣(厦门大学);倪赛凤(三星美国研究院);Madhukar Budagavi(三星美国研究院);郭小虎(德克萨斯大学达拉斯分校)。
归纳总结上述两种不同类型的属性,我们称第一类属性为显式属性,第二类为隐式属性。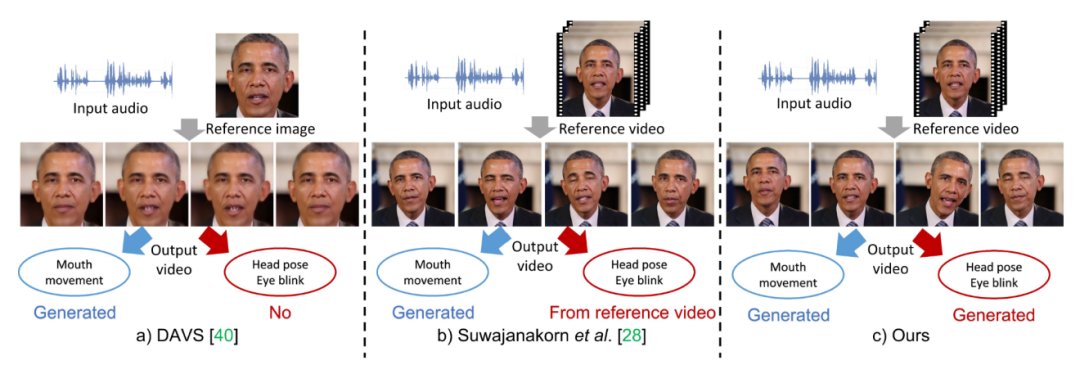
文章插图
尽管这些工作针对生成属性进行了不同侧面的探究,但是对这些属性的具体研究,仍存在以下问题:(1)显式和隐式属性如何潜在地相互影响?(2) 如何对隐式属性进行建模?例如头部姿势和眨眼等属性不仅取决于语音信号,还取决于语音信号的上下文特征以及与个体相关的风格特征。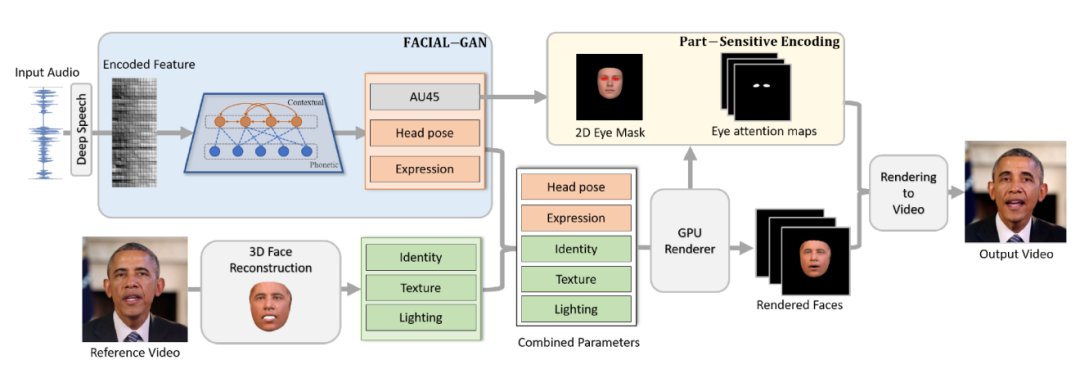
文章插图
如图2所示,我们提出了一个人脸隐式属性学习(FACIAL)框架来合成动态的谈话人脸视频。
(1)我们的 FACIAL 框架使用对抗学习网络联合学习这一过程中的隐式和显式属性。我们提出以协作的方式嵌入所有属性,包括眨眼信息、头部姿势、表情、个体身份信息、纹理和光照信息,以便可以在同一框架下对它们用于生成说话人脸的潜在交互进行建模。
(2) 我们在这个框架中设计了一个特殊的 FACIAL-GAN网络来共同学习语音、上下文和个性化信息。这一网络将一系列连续帧作为分组输入并生成上下文隐空间向量,该向量与每个帧的语音信息一起由单独的基于帧的生成器进一步编码。因此,我们的 FACIAL-GAN 可以很好地捕获隐式属性(例如头部姿势等)、上下文和个性化信息。
- text|《2021大数据产业年度创新技术突破》榜重磅发布丨金猿奖
- 分成|YY直播:2021年公会和主播分成超50亿
- 智能手机|全球第17位!App Annie报告:2021年中国人均每天用手机3.3小时
- App Annie:2021 年人们平均每天玩手机近 5 小时
- 核桃|核桃编程荣膺“2021中国网·科技企业先锋榜”年度品牌影响力企业
- 恶意软件|报告称 2021 年 Linux 的恶意软件样本数量增加了 35%
- QQ音乐的2021专辑盘点,是如何征服资深乐迷的
- 联想|联想背刺华为,联想也配?
- 在2021大中华区艾菲国际论坛上|玛雅文化施葵:新消费时代,如何助力品牌跑出“破圈”加速度?
- 新快报讯 记者张磊报道 2021年三季度|线上线下双“IQ”赋能,凯迪拉克LYRIQ打造更高维度的用户互联