FICCV 2021 | audi( 二 )
(3) 我们的 FACIAL-GAN 还可以预测眨眼信息,这些信息被进一步嵌入到最终渲染模块的眼部相关的注意力图中,用于在输出视频合成逼真的眼部运动信息。实验结果和用户研究表明,我们的方法可以生成逼真的谈话人脸视频,该生成视频不仅具有同步的唇部运动,而且具有自然的头部运动和眨眼信息。并且其视频质量明显优于现有先进方法。
文章插图
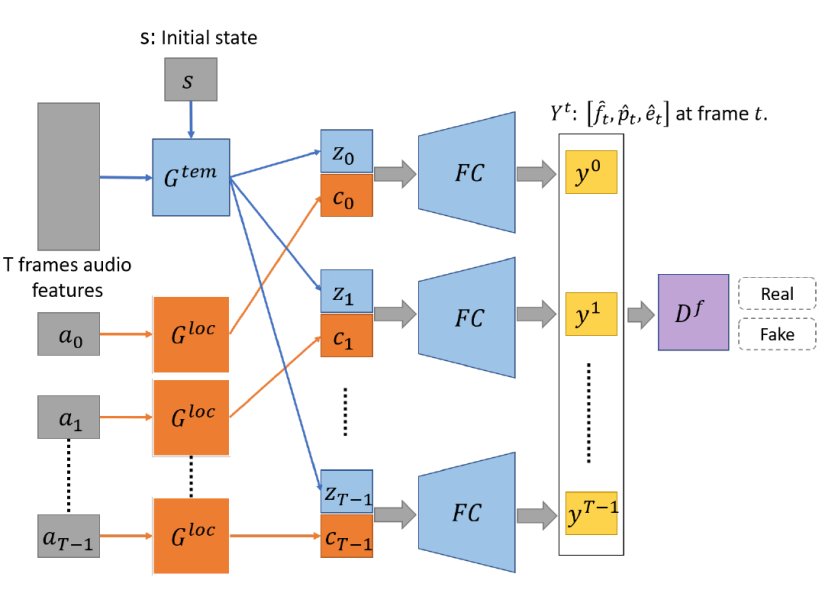
如图3所示,FACIAL-GAN 由三个基本部分组成:时间相关生成器用于构建上下文关系和局部语音生成器用于提取每一帧特征。此外,使用判别器网络来判断生成的属性的真假。(具体的网络细节请参考原文内容)
- 定性比较实验
如图4,图5,图6所示,我们与现有音频驱动的人脸视频生成方法进行比较。相比之下,通过显式和隐式属性的协同学习,我们的方法生成具有个性化的头部运动,考虑到不同个体的运动特性,同时可以生成更加逼真眨眼信息的人脸视频。(详细的比较结果请参考上述的视频链接)

文章插图

文章插图
- 定量比较实验

文章插图
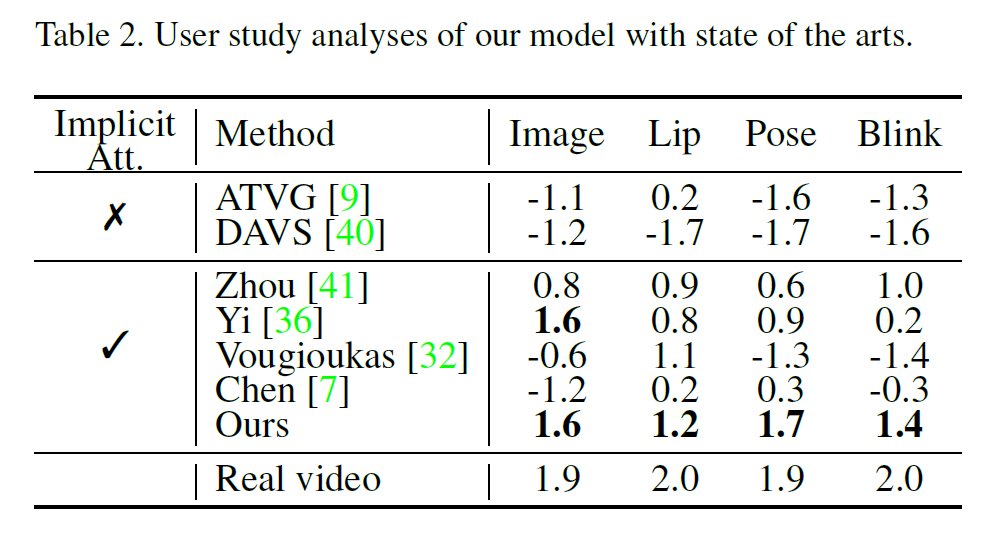
如表2所示,我们通过进行主观的用户研究(User Study),即从人类观察的角度比较生成的结果,其中更大的数值代表更优的生成质量和用户认可度。
文章插图
- text|《2021大数据产业年度创新技术突破》榜重磅发布丨金猿奖
- 分成|YY直播:2021年公会和主播分成超50亿
- 智能手机|全球第17位!App Annie报告:2021年中国人均每天用手机3.3小时
- App Annie:2021 年人们平均每天玩手机近 5 小时
- 核桃|核桃编程荣膺“2021中国网·科技企业先锋榜”年度品牌影响力企业
- 恶意软件|报告称 2021 年 Linux 的恶意软件样本数量增加了 35%
- QQ音乐的2021专辑盘点,是如何征服资深乐迷的
- 联想|联想背刺华为,联想也配?
- 在2021大中华区艾菲国际论坛上|玛雅文化施葵:新消费时代,如何助力品牌跑出“破圈”加速度?
- 新快报讯 记者张磊报道 2021年三季度|线上线下双“IQ”赋能,凯迪拉克LYRIQ打造更高维度的用户互联