智东西内参|行业首部DPU白皮书出炉!比肩CPU/GPU的数据时代核芯,巨头纷纷入场 | dpu( 三 )
3、异构计算的阶段性标志DPU的出现是异构计算的又一个阶段性标志。摩尔定律放缓使得通用CPU性能增长的边际成本迅速上升,数据表明现在CPU的性能年化增长(面积归一化之后)仅有3%左右,但计算需求却是爆发性增长,这几乎是所有专用计算芯片得以发展的重要背景因素。
摩尔定律的放缓与全球数据量的爆发这个正在迅速激化的矛盾通常被作为处理器专用化的大背景,正所谓硅的摩尔定律虽然已经明显放缓,但“数据摩尔定律”已然到来。IDC的数据显示,全球数据量在过去10年年均复合增长率接近50%,并进一步预测每四个月对于算力的需求就会翻一倍。
因此必须要找到新的可以比通用处理器带来更快算力增长的计算芯片,DPU于是应运而生。这个大背景虽然有一定的合理性,但是还是过于模糊,并没有回答DPU之所以新的原因是什么,是什么“量变”导致了“质变”?
从现在已经公布的各个厂商的DPU架构来看,虽然结构有所差异,但都不约而同强调网络处理能力。从这个角度看,DPU是一个强IO型的芯片,这也是DPU与CPU最大的区别。CPU的IO性能主要体现在高速前端总线(在Intel的体系里称之为FSB,Front Side Bus),CPU通过FSB连接北桥芯片组,然后连接到主存系统和其他高速外设(主要是PCIe设备)。目前更新的CPU虽然通过集成存储控制器等手段弱化了北桥芯片的作用,但本质是不变的。
DPU的IO带宽几乎可以与网络带宽等同,例如,网络支持25G,那么DPU就要支持25G。从这个意义上看,DPU继承了网卡芯片的一些特征,但是不同于网卡芯片,DPU不仅仅是为了解析链路层的数据帧,而是要做直接的数据内容的处理,进行复杂的计算。所以,DPU是在支持强IO基础上的具备强算力的芯片。简言之,DPU是一个IO密集型的芯片;相较而言,DPU还是一个计算密集型芯片。
进一步地,通过比较网络带宽的增长趋势和通用CPU性能增长趋势,能发现一个有趣的现象:带宽性能增速比(RBP,Ratio of Bandwidth andPerformance growth rate)失调。RBP定义为网络带宽的增速比上CPU性能增速,即RBP=BW GR/Perf. GR如下图所示,以Mellanox的ConnectX系列网卡带宽作为网络IO的案例,以Intel的系列产品性能作为CPU的案例,定义一个新指标“带宽性能增速比”来反应趋势的变化。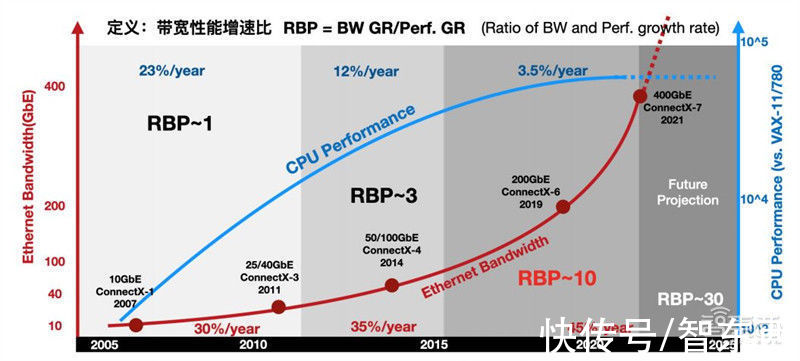
文章插图
带宽性能增速?(RBP)失调
2010年前,网络的带宽年化增长大约是30%,到2015年微增到35%,然后在近年达到45%。相对应的,CPU的性能增长从10年前的23%,下降到12%,并在近年直接降低到3%。在这三个时间段内,RBP指标从1附近,上升到3,并在近年超过了10!如果在网络带宽增速与CPU性能增速近乎持平,RGR~1,IO压力尚未显现出来,那么当目前RBP达到10倍的情形下,CPU几乎已经无法直接应对网络带宽的增速。RBP指标在近几年剧增也许是DPU终于等到机会“横空出世”的重要原因之一。
4、DPU发展历程随着云平台虚拟化技术的发展,智能网卡的发展基本可以分为三个阶段: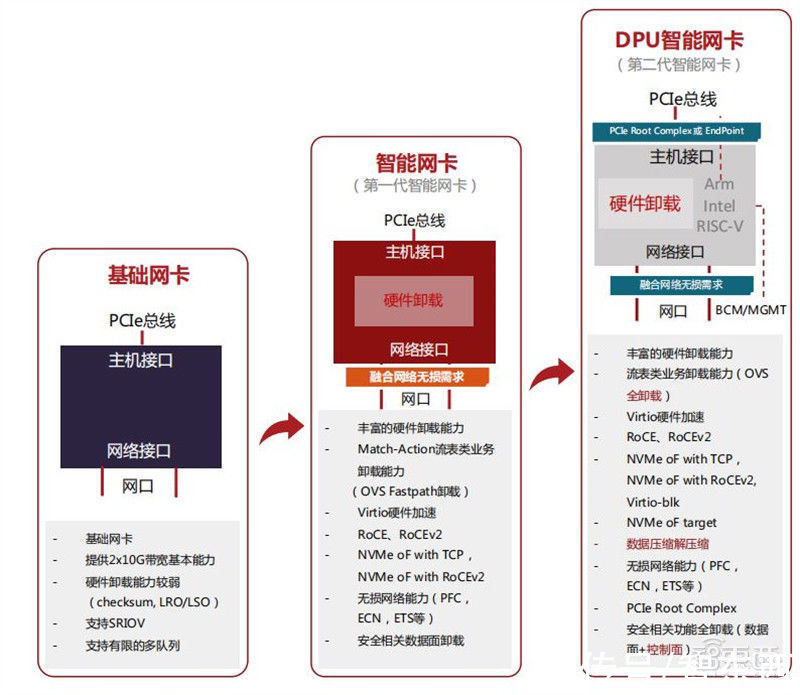
文章插图
智能?卡发展的三个阶段
随着越来越多的功能加入到智能网卡中,其功率将很难限制在75W之内,这样就需要独立的供电系统。所以,未来的智能网卡形态可能有三种形态:
(1)独立供电的智能网卡,需要考虑网卡状态与计算服务之间低层信号识别,在计算系统启动的过程中或者启动之后,智能网卡是否已经是进入服务状态,这些都需要探索和解决。
(2)没有PCIe接口的DPU智能网卡,可以组成DPU资源池,专门负责网络功能,例如负载均衡,访问控制,防火墙设备等。管理软件可以直接通过智能网卡管理接口定义对应的网络功能,并作为虚拟化网络功能集群提供对应网络能力,无需PCIe接口。
- 荣耀|今年过节不乱跑,荣耀智慧屏1499起,和年夜饭一样真香
- 苹果|国内首款支持苹果HomeKit的智能门锁发布:iPhone一碰即开门
- CPU|元宇宙+高端制造+人工智能!公司已投高科技超100亿,股价仅3元
- 智能|地震救人新突破!中科院研制出触嗅一体智能仿生机械手
- 智能制造|企业转型的新时代,夹缝中求生存
- DeepMind首席科学家:比起机器智能,我更担心人类智能造成的灾难
- Aqara 智能门锁 A100 Pro 发布:支持苹果“家庭钥匙”解锁
- 资讯丨智能DHT+高阶智能驾驶辅助,魏牌开启“0焦虑智能电动”新赛道
- 智能手机|全球第17位!App Annie报告:2021年中国人均每天用手机3.3小时
- 赵明路|华为终端申请注册鸿蒙智联商标,国际分类涉服装鞋帽