lun不一样的科大讯飞,他们把计算机视觉踢进“世界杯”( 三 )
吴嘉嘉开始形成自己的方法论——他山之石,可以攻玉。
技术的进步常比想象中走得更快,而在发展之前,则是默默耕耘与长期投入。
在OCR生根发芽之际,科大讯飞又开启了计算机视觉领域其他技术方向探索的征程,从人脸识别、医学影像到辅助驾驶、虚拟形象。
科大讯飞对于新方向的探索多是从参与国际顶尖比赛开始的,探索技术的可达性。
2016年,人工智能+医疗概念逐步兴起,作为医疗影像领域最具代表性、最受关注的国际测评任务之一,LUNA(LUng Nodule Analysis)测评吸引了大批国内外学术界和产业界的团队参与。但 LUNA任务的难度系数极高,核心原因在于肺结节检测输入的信息量巨大,而目标非常小。
参与LUNA比赛是殷保才投身医疗后的第一个任务。
几乎所有参赛团队都采用了2D或2.5D的解决方案,其中2D方案就是只处理单张影像;2.5D则是通过纵向、斜向地对整个影像序列切割出2D数据,再进行处理。
“但这些方案都不可避免导致原始信息的丢失,必须用3D模型。”
文章插图
因为LUNA所要处理的数据是3D数据。所谓3D数据,即CT影像是一个数百张影像的集合,每一张通过扫描身体部位的一个断层得到。所谓3D框架,指的是其专门用于处理3D形式的数据。在竞争榜单上,殷保才是少有的熟知尚不成熟的3D图像识别技术的人。
不难看出,这种解决方案简单直接,与问题本身天然匹配。
在这场比赛中,殷保才团队开发的框架最终获得了94.1%的召回率(召回率高意味着对阳性患者的漏诊率低),这一成绩也刷新了当时的榜单世界纪录。
“才子”的这种源源不断的直觉,其实离不开长期的技术积累沉淀。
吴嘉嘉团队此时已解决了文本行识别,正在为突破公式识别而努力。传统文本行识别都是非常定式的从左到右、从上到下的识别顺序,模式比较单一。而公式会有各种嵌套结构、左右上下的杂糅。
分数加法算式就是一个左右上下混合的简单例子,比如1/5是一个上下结构,1/5+2/5又是一个左右结构。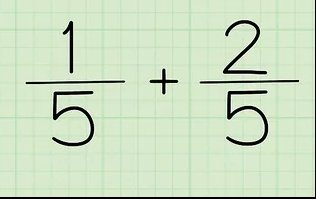
文章插图
文章插图
后来源于科大讯飞研究院在机器翻译上的技术积累,他们发现公式识别任务和机器翻译任务很像,因此可以把基于注意力机制的Encoder-Decoder模型运用到公式识别上来。
在语音识别技术和自然语言理解技术领域所使用的序列建模和神经网络中的注意力机制,成为OCR技术“灵感的缪斯”。进一步地,团队联合NELSLIP基于Encoder-Decoder模型构建了新的无切分公式识别算法。
不到一年的时间,吴嘉嘉团队在公式识别上已经达到了96%的准确率。
随后,在国际顶级手写公式识别挑战赛中,团队先后获得2019年ICDAAR CROHME、2020年ICFHR OffRaSHME多个国际冠军。
- 副董事长|京东方A董秘回复:公司与全球数千家供应商保持着良好的合作关系
- 电池|vivoY55s,能有效解决你的续航焦虑!
- 微信|个人收款码与商业收款码有什么不一样
- 加盟行业|原来加盟行业是这么玩的!
- 京东|适合过年送长辈的数码好物,好用不贵+大牌保障,最后一个太实用
- 儿童教育|首个播放量破 100 亿的 YouTube 视频诞生,竟然是儿歌
- 苹果|国内首款支持苹果HomeKit的智能门锁发布:iPhone一碰即开门
- 小米科技|预算只有两三千买这三款,颜值性能卓越,没有超高预算的用户看看
- 苹果|苹果最巅峰产品就是8,之后的产品,多少都有出现问题
- 普莉希拉|祖籍徐州的普莉希拉,嫁全球第5富豪扎克伯格,坐拥6530亿被说丑