文章图片

文章图片
数据挖掘在商业领域 , 特别是在零售业的运用是比较成功的 。 由于各业务系统的普遍使用 , 再加上商业智能BI的可视化分析 , 企业可以收集到大量关于购买情况的数据 , 并且数据量在不断激增 。 利用数据挖掘技术可以为经营管理人员提供正确的决策手段 , 这样对促进销售及提高竞争力是有帮助的 。
一、什么是数据挖掘
所站立场不同 , 对数据挖掘的定义也是不一样的 。
1. 技术上的定义
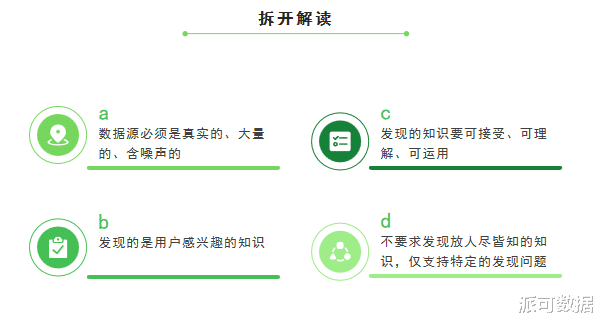
数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中 , 提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程 。
2. 商业角度的定义
数据挖掘是一种新的商业信息处理技术 , 其主要特点是对商业数据库中的大量业务数据进行抽取、转换、分析和其他模型化处理 , 从中提取辅助商业决策的关键性数据 。
因此 , 数据挖掘可以描述为:按企业既定业务目标 , 对大量的企业数据进行探索和分析 , 揭示隐藏的、未知的或验证已知的规律性 , 并进一步将其模型化的先进有效的方法 。
二、数据挖掘的分类
数据挖掘分为有指导的数据挖掘和无指导的数据挖掘 。 有指导的数据挖掘是利用可用的数据建立一个模型 , 这个模型是对一个特定属性的描述 。 无指导的数据挖掘是在所有的属性中寻找某种关系 。 具体而言 , 分类、估值和预测属于有指导的数据挖掘;关联规则和聚类属于无指导的数据挖掘 。
分类
它首先从数据中选出已经分好类的训练集 , 在该训练集上运用数据挖掘技术 , 建立一个分类模型 , 再将该模型用于对没有分类的数据进行分类 。
估值
估值与分类类似 , 但估值最终的输出结果是连续型的数值 , 估值的量并非预先确定 。 估值可以作为分类的准备工作 。
预测
它是通过分类或估值来进行 , 通过分类或估值的训练得出一个模型 , 如果对于检验样本组而言该模型具有较高的准确率 , 可将该模型用于对新样本的未知变量进行预测 。
关联
关联的目的是发现某些事情总是一起发生 。
聚类
它是自动寻找并建立分组规则的方法 , 它通过判断样本之间的相似性 , 把相似样本划分在一个簇中 。
三、数据分析和数据挖掘的区别
数据分析 , 是用适当的统计方法对收集的海量数据进行分析、提取有用的信息和形成结论 , 然后对数据加以详细研究和概括总结的过程 。
数据挖掘 , 是从海量的数据中通过相应的算法 , 挖掘其中有价值(未知的、有规律的)的信息的复杂过程 。
数据挖掘是深层次的数据分析 , 数据分析是浅层次的数据挖掘 , 数据挖掘更偏重于探索性数据分析 , 因为数据挖掘的重点是从数据中发现知识规律 。
四、应用领域
搜索引擎:数据挖掘技术应用到搜索引擎领域 , 从而产生智能搜索引擎 , 将会给用户提供一个高效、准确的检索工具 。
金融领域:可以利用数据挖掘对客户信誉进行分析 。 典型的金融分析领域有投资评估和股票交易市场预测 。
数据挖掘还可用于工业、农业、交通、电信、军事、互联网等其它行业 。 数据挖掘具有广泛的应用前景 , 它既可应用于决策支持 , 也可用于数据库管理系统中 。
- 华为|不会自燃 寿命更长!华为在新能源憋大招:投资固态电池公司
- 鼠标|如何将太宽的表格打印在一张纸上?这7种方法,总有一个适合你
- 蚂蚁森林|马云曾经承诺每年要在沙漠种1亿棵树,6年过去了,那些树怎样了?
- web3|你现在多久换一次手机呢?不少用户肯定是用到不能用为止
- 求职招聘|男子在公司群质疑绩效、抱怨拖薪:结果被辞退
- 双十一|广告寒冬,为什么美妆企业还在大肆“花钱”?
- 腾讯|成龙、周星驰经典影片在内!腾讯视频百部高清修复版港片上线
- 苹果招募工程师助力6G建设,各国齐发力,6G网络有望在2030年推出
- 短视频|学全媒体运营在三四线城市好找工作吗?工资怎么样?
- Apple Watch|Apple Watch现在都开始卷起了快充