
文章插图
燧原科技第二代云端AI推理卡云燧i20
据张亚林分享,在多项基准测试中,云燧i20加速卡的模型性能、能效比均处于国内领先水平。
浪潮信息与燧原科技通过元脑生态联合创新,在AI整机系统、AI算力优化、场景方案落地等多方面深入合作。浪潮信息副总裁刘军评价道:“此次云燧i20的发布,标志着燧原从训练到推理全面进入2.0时代,这也是国产AI算力发展的里程碑。”
二、业内首个超大带宽推理加速卡,打出软硬协同系统组合拳与第一代推理产品云燧i10相同,云燧i20主要面向泛互联网、传统行业和新基建等赛道。
该AI推理加速卡支持视觉检测跟踪分类、语音识别与合成、自然语言处理等主流AI应用场景,并进一步提升了模型覆盖和泛化支持能力。
搭载于云燧i20的新一代“邃思”采用12nm工艺、第二代高性能计算核心和数据引擎,通过升级其自研架构GCU-CARA(通用计算单元和全域计算架构),大大提高了单位面积的晶体管效率,实现堪与当前业内7nm GPU匹敌的计算能力。

文章插图
得益于12nm成熟工艺带来的成本优势,云燧i20在相同性能表现下更具性价比优势,且供应链体系更加稳定成熟,能及时满足客户的业务需求。
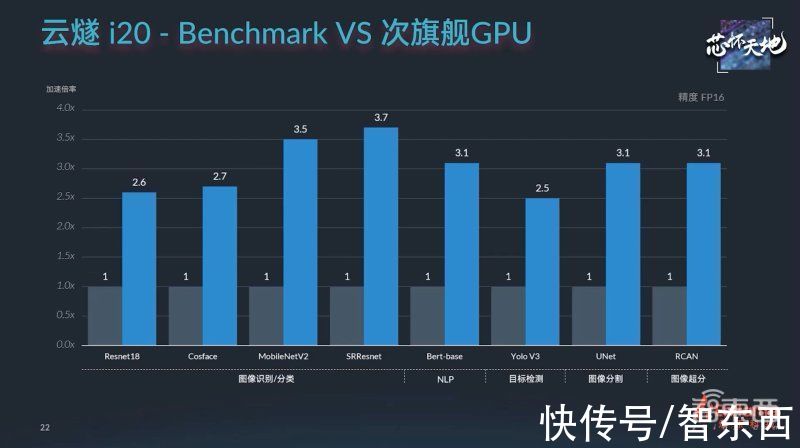
从算力规格来看,其目标实现得相当不错:
文章插图
计算方面,云燧i20全面支持从FP32、TF32、FP16、BF16到INT8的计算精度,并在兼顾全精度算力的同时,大幅提高了整型运算。
其单精度FP32峰值算力达到32TFLOPS,单精度张量TF32峰值算力达到128TFLOPS,整型INT8峰值算力达到256TOPS。
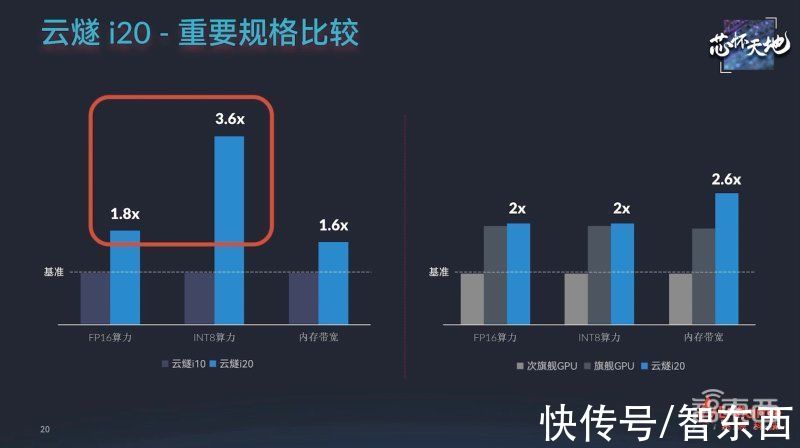
通过软硬件技术多重优化,云燧i20大幅提升了推理性能,浮点算力较云燧i10提升到1.8倍,整型算力提升到3.6倍。
与主流旗舰GPU相比,云燧i20的模型性能可以对标英伟达A10,是T4的2.5~3倍,并在性能深度优化能力、成本方面更具优势。
文章插图
存储方面,云燧i20拥有迄今业内最大的云端AI加速卡存储带宽。
此前燧原科技第二代云端AI训练芯片在国内率先支持HBM2E高带宽存储方案。如今云燧i20推理加速卡更进一步,基于HBM2E可提供超越同类产品水平的819GB/s超大存储带宽,为各类云端推理业务提供高吞吐、低延时的性能。
如今神经网络参数越来越多,无论是语音识别、图片识别、视频内容分析等感知类应用,还是内容推荐、欺诈交易拦截等决策类AI应用,在云端大部分都是以实时在线的方式提供服务,对数据带宽的需求不断上涨。而速度更快、密度更高的内存,有助于高端处理器兼顾高带宽和低延迟,保障AI相关服务准确、平稳、高效的运行。
软件方面,根据客户反馈的需求,燧原将其推理软件栈驭算进一步升级,使其在性能、开发效率和模型覆盖面上得到大幅提升。

文章插图
驭算引入了通用高层图优化和大规模算子融合技术,充分释放了大容量片内存储和高带宽存储的利用率,将模型平均性能提升3.5倍,硬件算力利用率平均提升2倍。
为了更加匹配客户开发习惯,驭算通过升级的编程模型以及算子自动分片、自动生成技术,使得自定义算子开发效率翻倍,大大降低模型迁移成本。驭算还增强了对动态性的支持,使云燧i20在检测、语音识别、语义理解等场景更具竞争力。
- 算力|不靠显卡!NVIDIA在中国焕发第二春:自动驾驶芯片被车厂爆买
- 天玑9000|独立AI+高算力ISP旗舰影像必备,联发科方向对了!天玑9000拍照技术拉满
- 智能|黑芝麻智能大算力芯片年内上车,首批车型将是自主品牌
- 安霸高管揭秘5nm自动驾驶芯片:500eTOPS算力从这来
- 冯羽涛|安霸高管揭秘5nm自动驾驶芯片:500eTOPS算力从这来
- 大智移云|湖南将升级改造国家超算长沙中心 建成全国先进的绿色算力枢纽
- poc|?中兴通讯联合中国联通完成算力网络服务调度PoC验证
- ABF载板|郭明錤:苹果AR/MR设备均搭载双CPU,运算力领先竞争对手2–3年
- 电视|海信发布中国首颗全自研8K AI画质芯片:双路CPU、画质算力天花板
- 自动驾驶|焦点分析|从全球霸主到算力掉队,这家芯片公司决定撕掉“封闭”标签