文章图片
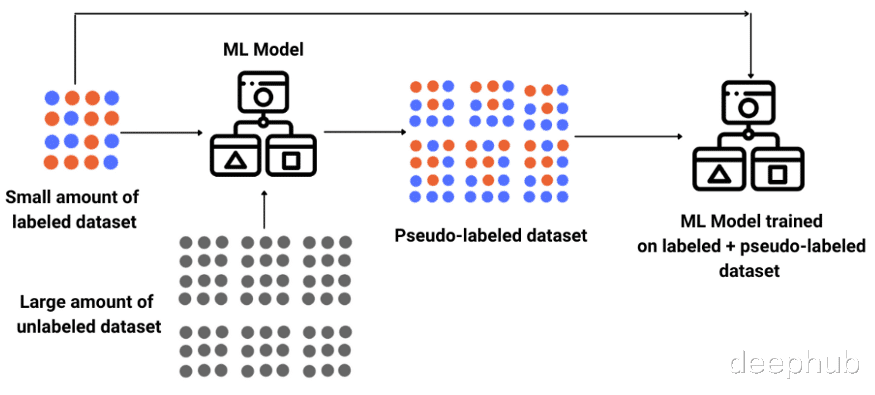
深度神经网络已被证明在对大量标记数据进行监督学习的训练中是非常有效的 。但是大多数现实世界的数据并没有被标记 , 并且进行全部标记也是不太现实的(需要大量的资源、时间和精力) 。为了解决这个问题半监督学习 ( semi-supervised learning) 具有巨大实用价值 。SSL 是监督学习和无监督学习的结合 , 它使用一小部分标记示例和大量未标记数据 , 模型必须从中学习并对新示例进行预测 。基本过程涉及使用现有的标记数据来标记剩余的未标记数据 , 从而有效地帮助增加训练数据 。图 1 显示了 SSL 的一般过程 。
根据系统的目标函数 , 有几种类型的半监督系统 , 例如半监督分类、半监督聚类和半监督回归 。在本文中 , 我们主要回顾图像的单标签分类 。
SSL 中有两种主要的学习范式 , transductive learning 和 inductive learning 。
- transductive learning不会为整个输入空间构建分类器 。所以此类系统没有单独的训练和测试阶段并仅限于对其进行训练的目标对象进行预测 。
- inductive learning可以预测输入空间中的任何对象 。这个分类器可以使用未标记的数据进行训练 , 但是一旦训练完成 , 它对之前未见对象的预测是相互独立的 。
如果对数据的分布做出某些假设 , SSL的性能可能会得到很大的改进 。
- 自训练假设:具有高置信度的预测被认为是准确的
- 协同训练假设:实例 x 有两个条件独立的视图 , 每个视图都足以完成分类任务 。
- 生成模型假设:当混合分量的数量、先验 p(y) 和条件分布 p(x|y) 正确时 , 可以假设数据来自混合模型 。
- 聚类假设:同一簇中的两个点x1和x2应该被分成相同类 。
- 低密度分割(Low-density separation):以低密度区域作为边界 , 而不是高密度区域(非黑既白) 。
- 流形假设:如果两点x1和x2位于低维流形的局部邻域内 , 它们具有相似的类别标签 。
生成模型GAN 是一种无监督模型 。它包括一个在未标记数据上训练的生成模型 , 以及一个确定生成器质量的判别分类器 。生成模型可以学习数据的隐含特征 , 然后根据相同的分布生成一组新的数据 。换句话说 , 能够从数据分布P(x)生成数据的生成模型 , 必须学习可转移到目标为“y”的监督任务P(x|y)的特征 。
半监督 GANS
GAN能够从未标记样本中了解真实数据的分布 , 这有利于SSL 。 在如何将GAN用于SSL方面有四个主要步骤 。
- 重用鉴别器的特性
- 使用gan生成的样本来正则化分类器
- 使用GAN生成的样本作为额外的训练数据
- 学习新的训练推理模型
- CatGAN:Categorical Generative Adversarial Network (CatGAN) 修改了 GAN 的目标函数 , 以合并观察到的样本与其预测的分类分布之间的互信息 。 它的目标是训练一个鉴别器 , 通过将 y 标记到每个 x 来将样本区分为 K 个类别 , 而不是学习二元鉴别器值函数 。
- CCGAN:Context-Conditional Generative Adversarial Networks (CCGAN) 使用对抗性损失来利用未标记图像数据的方法 , 例如图像修复 。 上下文信息由图像的周围部分提供 。 生成器经过训练以在缺失的图像片段中生成像素 。
- 东南亚|MIUI13深度使用报告,这还是我认识的MIUI吗?网友评价很真实
- 将理论注入深度学习,对过渡金属表面进行可解释的化学反应性预测
- 《吉星高照》的谢怜杀青啦,半年的拍摄
- 家庭影院|深度设置和调节家庭影院低音炮
- 人类的工作会被AI取代吗?如果机器能够深度学习|为什么说AI能作巴赫的曲,却写不出村上春树的小说?
- 新年新气象。|深度 | 创造“世界记录”!江苏这个王牌实验室为何收获多?
- ios|时隔两个半月,微信 iOS 版迎来 8.0.17 正式版更新
- 中国半导体产业进入了技术驱动成长期 半导体及元件板块短线拉升|板块异动 | 拉升
- 芯片|半导体行业大赚!2021年第一季度19家企业宣布涨价
- 巴黎协定|纳微半导体成立全球首家电动车氮化镓功率芯片设计中心