G可解释 生物医学( 三 )

文章插图
当时我们也推出了一款新产品,命名为ShouZhuo,成功打败了AlphaGo,并尝试继续迭代算法,一举写出一篇好论文。不幸的是,两周以后Alpha Zero出来了。它不断跟自己对弈,不需要五千年的棋谱,练到最后棋法越来越好,把所有人类都打败了。
我们的想法是类似的,但是我们为什么不能成功呢?我们发觉,假如我们的算法也像Alpha Zero这样无休止对弈、训练,凭借我们实验室的硬件,大概要用1000多年的时间,1000多年之后这个算法肯定就没用了。
说到底,人工智能还不聪明,还是依靠“数据+硬件”驱动。在拼设备的年代,还能拼什么?
所以,这时出现了第三代AI系统。它将知识和数据结合起来,融汇了第一代AI系统和第二代AI系统。

文章插图
举个例子,什么叫知识驱动?我女儿两岁的时候被蜜蜂蛰了一个大包,以后再见到蜜蜂就会跑开,这是数据驱动。什么是知识驱动呢?从小你家里人告诉你,猫不能碰、狗不能碰、蜜蜂不能碰、蛇不能碰,以后你见到这些东西就会远离。
但是知识驱动是有缺点的,因为图片是有限的,以后你遇到老虎、遇到大象还是会碰,因为没有先验知识。数据驱动也是有问题的,需要通过大量的数据完成“原始学习”,过程很慢。
如何将两种学习方式结合起来,将知识嵌入到机器脑中,这是第三代AI系统的问题。

文章插图
举个例子,假如现在用100万张猫和狗图像训练好了一个神经网络,也就是设置好了参数,它会很轻松地分辨猫还是狗,但是准确性如何升高,如何再调整参数?

文章插图
这时候就要用到梯度调节,这就是神经网络的概念。但是如何通过知识驱动,就是嵌入一个概念:比如我把“狗的耳朵比较大,猫的鼻子比较小”的概念放进去,这个算法就可以学得更好、更快。
所以,如何将知识图谱注入神经网络是很重要的课题。

文章插图
举个例子,用神经网络抠出图片中的人。左边的图为无监督分隔,没有嵌入足够的知识图谱,所以分隔得十分粗糙。而右边的图为半监督分隔,事先学习了天是蓝的、云是白的、人脸是黄的,人的衣服是黑色的知识,图像识别的效果非常好。

文章插图
同样的知识学习还体现在AI识别手写0—9这10个数字的实验中。
尽管每个人的笔迹都不同,写字风格千差万别,但假如我事先编写一组规则:有圆圈就是0、6、8、9,有一竖的就是1、4、7等等,这样AI的识别结果会好很多。

文章插图
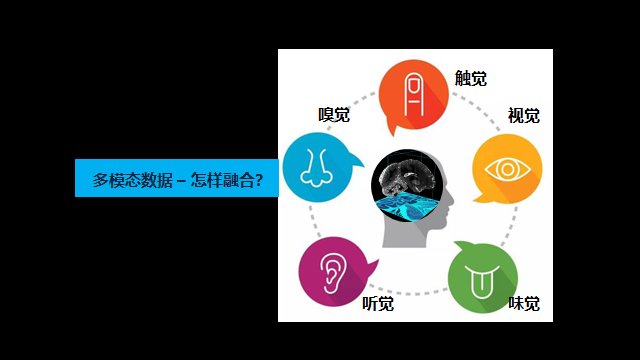
另一个方法是融合多模态数据,是把所有数据融合起来决策。
要预测什么菜好吃,我们说闻起来很香,炒起来看着很好吃,味道很甜美,口感很滑,颜色很漂亮,这就是好菜。
但是我要给你一个融合的算法,告诉你这个菜是臭的(臭豆腐),吃起来是很香的,颜色也是很糟糕的,你说是好还是不好?这个决策就很难了。
所以,这里面的融合,要决定哪个因素有多少的比例,大家投票说臭豆腐好不好,来训练这个神经网络。
- 将理论注入深度学习,对过渡金属表面进行可解释的化学反应性预测
- 00后医学生两年后如愿参与抗疫
- |人类关节病治疗迈出一大步,奔跑吧!用你的“生物改造膝盖”
- A股|国际医学股票被ST 1月14日开市起停牌:14万股民懵了
- 信华生物|经纬创投领投,AI驱动大分子药物研发企业信华生物完成1亿元Pre-A轮融资
- 细胞分布|3D打印让微生物“互掐”变“协作”,最大化生物过程效率
- 达尔文生物完成A+轮融资 国家中小企业发展基金领投
- 算法|腾讯研究院发布《可解释AI发展报告2022》 探讨AI伦理走向
- sensec全球AI医学影像辅助诊断发明专利排行榜公布,商汤荣登全球第五
- 新冠病毒|金域医学:丢样本伪造数据、主动传播病毒传言不实 请公众勿造谣传谣