
文章图片
文章图片
文章图片

文章图片
前言 近年来 , Kubernetes作为众多公司云原生改造的首选容器化编排平台 , 越来越多的开发和运维工作都围绕Kubernetes展开 , 保证Kubernetes的稳定性和可用性是最基础的需求 , 而这其中最核心的就是如何有效地监控Kubernetes集群 , 保证整个集群的一个良好的可观察性 。 本期将为大家介绍Kubernetes的监控方案 。
监控方案目标 目前存在多套的Kubernetes监控方案 , 但实际实施起来可能会遇到很多问题 , 例如方案部署难、监控指标不准、没有合适的大盘、不知道哪些指标需要哪些不需要、数据太多很卡等等 。 其实这些问题的本质上还是因为Kubernetes的架构相对标准的虚拟机/物理机的方式要复杂很多 , 而面对复杂系统 , 就需要我们去做非常多的工作 , 例如:
【kubernetes|简单、有效、全面的 Kubernetes 监控方案】
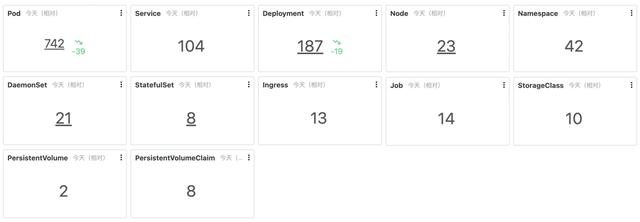
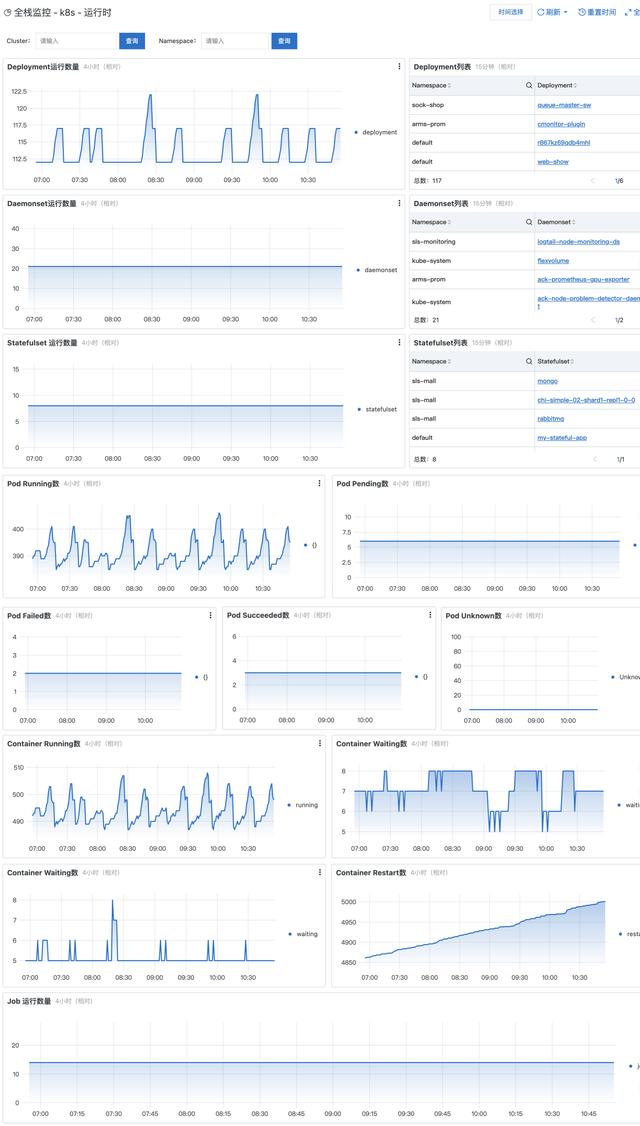
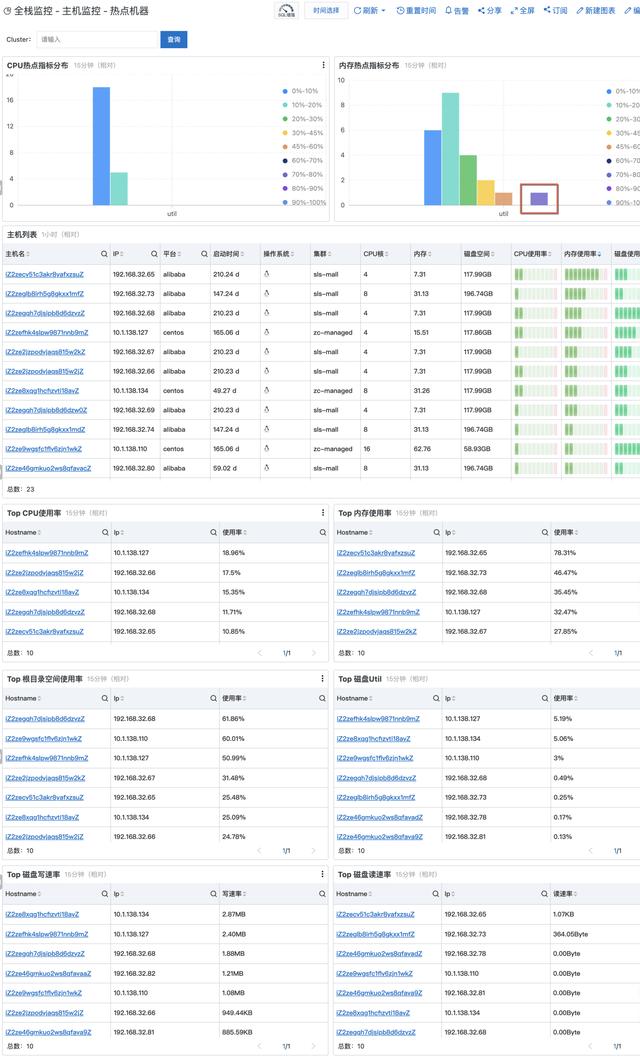
明确监控目标:K8s内部的各类系统组件:APIServer、ETCD、Scheduler、Controller Manager、Kubelet等;K8s底层 , 例如虚拟机、物理机的监控;K8s之上的业务/出口等 相关监控数据采集:例如部署kube-state-metrics采集K8s内资源对象的数据;通过kubelet暴露的prometheus端口拉取运行的Pod、容器指标;通过service端口采集APIServer、ETCD、Scheduler等组件的指标 后端建设:搭建数据存储、可视化、告警等后端服务 内容建设:配置监控大盘、问题排查经验、每个组件监控的黄金指标、告警模板等 方案稳定性建设:包括数据采集、存储、可视化、告警等服务的质量监控和维护 SLS全栈监控方案 SLS作为阿里可观测性数据引擎 , 具备可观测数据日志、指标、分布式链路追踪、事件等的一站式采集和存储 。 为了便于用户快速接入和监控业务系统 , SLS提供了全栈监控的APP , 将各类监控数据汇总到一个实例中进行统一的管理和监控 。 全栈监控基于SLS的监控数据采集、存储、分析、可视化、告警、AIOps等能力构建 , 详细功能如下: 实时监控各类系统 , 包括主机监控、Kubernetes监控、数据库监控、中间件监控等 。支持ECS、K8s一键安装 , 支持图形化的监控配置管理 , 无需登录主机配置采集监控项 。运维老司机多年经验的报表总结 , 包括资源总览、水位监控、热点分析、详细指标等数十个报表 。支持自定义的分析 , 支持包括PromQL、SQL92等多种分析语法 。支持对接AIOps指标巡检 , 利用机器学习技术自动发现异常指标 。支持自定义告警配置 , 告警通知直接对接消息中心、短信、邮件、语音(电话)、钉钉 , 并支持对接自定义WebHook 。Kubernetes监控最佳实践 SLS全栈监控已经内置了对于Kubernetes监控的支持 , 并且解决了非常多的Kubernetes监控的痛点需求 , 例如: 部署简单 , 只需要一条命令就可以部署完整的Kubernetes监控方案 使用简单 , 内置了多种Kubernetes以及上下游相关的监控报表 , 开箱即用 运维简单 , 所有的监控数据、报表、告警等后端都是云化 , 只需要按量付费即可 , 无需去运维监控的实例 覆盖面全 , 监控范围包括Kubernetes中的各种内置组件 , 也包括相关联的主机、中间件、数据库等监控 部署 SLS全栈监控的Kubernetes部署方式相对比较简单 , 只需要按照接入页面中的提示 , 安装AliyunLogConfig自定义资源和监控组件 , 两个安装步骤只需要执行两个命令即可 。相关参考(1. 创建全栈监控实例;2. 创建Kubernetes监控) 使用 Kubernetes监控部署完毕后就会自动部署采集Agent并采集监控数据到云端 , 默认采集的监控数据有: Kubernetes系统的元数据信息 , 例如节点、Pod、Deployment等配置信息 Kubernetes系统组件的监控数据 , 包括APIServer、ETCD、Kubelet等 Kubernetes上运行的Deployment、StatefullSet、DaemonSet、Pod、容器指标信息 节点的基础指标 , 例如节点CPU、内存、网络、磁盘IO等 数据采集到云端后 , SLS全栈监控会默认提供一系列的Dashboard模板 , 包括集群级、应用级(Deployment、StatefullSet、DaemonSet等)、Pod级各类指标 , 绝大部分场景的监控只需要使用内置的Dashboard大盘即可 , 内置大盘主要有: 仪表盘 说明 资源总览 用于实时可视化展示主机配置信息和指标信息的总体情况 , 包括CPU核数、磁盘总空间、CPU平均使用率、内存平均使用率等 。主机列表 用于实时可视化展示每台主机的配置信息和指标信息 , 包括CPU核数、内存、CPU使用率、内存使用率等 。热点分析 用于实时可视化热点机器的CPU、内存等资源使用情况 , 包括CPU热点指标分布、内存热点指标分布、Top CPU使用率、Top 内存使用率等 。单机指标-简 用于实时可视化展示主机的CPU、内存等资源的使用趋势 , 包括CPU使用率、磁盘空间使用率、内存使用率等 。单机指标-详 用于实时可视化展示主机的CPU、内存等资源处于不同状态的使用趋势 , 包括CPU(处于Total、System、User、IOWait状态的CPU使用趋势)、内存(处于Total、Availableused、Used状态的内存使用趋势)等 。资源总览 用于实时可视化展示Kubernetes中资源的使用情况 , 包括Pod、Host、Service、Deployment等 。水位监控 用于实时可视化展示Kubernetes中资源的水位情况 , 包括Pod运行数、CPU总数、文件系统使用量等 。运行时监控 用于实时可视化展示Kubernetes中处于运行状态的资源信息 , 包括Deployment运行数量、Daemonset运行数量等 。核心组件监控 用于实时可视化展示Kubernetes中核心组件的相关数据 , 包括ETCD对象数、ETCD请求QPS等 。Node列表 用于实时可视化展示Node的整体情况以及每个Node的配置信息和指标信息 , 包括Node总数、运行中的Pod总数等 。Node指标 用于实时可视化展示Node的指标信息 , 包括可申请Pod数量、CPU使用率等 。Pod列表 用于实时可视化展示Pod的整体情况以及每个Pod的配置信息和指标信息 , 包括可申请的Pod总数等 。Pod指标 用于实时可视化展示Pod的指标信息 , 包括Pod基本信息、容器基础信息等 。Deployment列表 用于实时可视化展示每个Deployment的配置信息和指标信息 , 包括Deployment所属命名空间、集群等 。Deployment指标 用于实时可视化展示Deployment的指标信息 , 包括CPU Limit使用率、内存Limit使用率等 。StatefulSet列表 用于实时可视化展示每个StatefulSet的配置信息和指标信息 , 包括StatefulSet所属命名空间、集群等 。StatefulSet指标 用于实时可视化展示StatefulSet的指标信息 , 包括CPU Limit使用率、内存Limit使用率等 。DaemonSet列表 用于实时可视化展示每个DaemonSet的配置信息和指标信息 , 包括DaemonSet所属命名空间、集群等 。DaemonSet指标 用于实时可视化展示DaemonSet的指标信息 , 包括CPU Limit使用率、内存Limit使用率等 。1 集群级监控实践 在K8s迭代了数十个版本后 , 集群本身的稳定性一般不需要关心 , 绝大部分情况下 , 都是使用的不合理影响了集群的稳定性 。 通常情况下 , 集群级别监控只需要关注集群中运行的应用数量变化以及相关的水位变化 。 这里最常见的是使用《资源总览》、《水位监控》和《运行时监控》 。 其中 资源总览中能够查看每个资源的总数以及和前一天相比的变化情况 , 用来监控是否有一些快速变化的资源出现 水位监控中主要显示集群中能够申请的Pod、CPU、内存资源以及当前的申请率信息 , 防止到达水位上限 运行时监控中主要显示集群中的Deployment、StatefullSet、Pod、Container的变化情况 2 系统组件监控实践 同样 , K8s的系统组件监控 , 通常只需要关心其中使用部分的不合理即可 , 因此只需要查看其中APIServer和ETCD的部分 , 防止有非常多的额外资源和访问导致APIServer或ETCD请求过慢 。3 应用基础指标监控 全栈监控默认提供了Node、Pod、Deployment、DaemonSet、StatefullSet的基础指标监控 , 所有这些资源都包括列表的Overview指标以及详情的Detail指标 , 而且各个相关联的资源还支持跳转关系 , 例如:所有的列表支持跳转到详情的Detail指标、Node中支持关联运行的Pod指标、Deployment/DaemonSet/StatefullSet支持跳转关联Pod 。4 热点监控 热点监控主要辅助我们快速找到“离群”的机器 , 防止因为部分机器成为热点 , 导致该机器上应用响应变慢 , 以至于影响整个集群的性能 。 在找到热点机器后 , 还可以通过改机器的IP , 跳转到对应Node的详细指标中 , 查看热点具体是由该节点上哪个Pod引起 。小结 本文主要关注在Kubernetes的监控方案上(如何接入可参考《全栈监控说明》) , 从监控的问题发现到定位其实还有很多的工作需要做 , 还需要更多的可观测性数据来支撑 , 后续我们会介绍 , 如何利用多种可观测数据来协助排查和定位Kubernetes中的各类问题 , 敬请期待 。原文链接:https://developer.aliyun.com/article/852141?utm_content=g_1000319408 本文为阿里云原创内容 , 未经允许不得转载 。
- 本文转自:江西新闻广播江西新闻广播讯(记者刘宜河、余月萌) 1月18日|“亚洲锂都”积极推进“5G+工业互联网”赋能产业转型升级
- 程序员|中国银联:程序员就该用RTX 3090、64GB内存写代码
- 自媒体|做自媒体赚钱就只是一个行业这么简单吗?
- GitHub|git、github、gitlab有什么区别?
- 本文转自:国际在线伴随我国思专翟无障碍设施建设、无障碍信息服务不断完善|优化无障碍服务,微众银行微粒贷一直在努力
- 苹果|3.4亿台!2021年全球电脑出货量出炉:联想第一、苹果第四
- 本文转自:北青网(记者张爱虎、通讯员王俊、晏家和)省财政厅19日介绍|动动手指 贷款到手 湖北上线政府采购合同手机贷款功能
- 腾讯|中交集团携手腾讯推出“骄子微卡”:实名管理、薪酬无忧
- 淘宝发布2022年直播激励计划,现金激励、扶持中腰部及新达人
- mcn|小红书起诉微媒通告等4家涉虚假种草通告平台、MCN机构