mb|IBM,预言了缓存的未来?( 二 )
如果缓存的目的是将数据靠近核心,那么任何时候缓存中的数据没有准备好,就称为缓存未命中——任何 CPU 设计的目标都是尽量减少缓存未命中,以换取性能或功率,因此具有明确定义的工作负载,
延迟也是设计大缓存的一个重要因素。
您拥有的缓存越多,访问所需的时间就越长——不仅因为物理大小(以及与核心的距离),还因为有更多的缓存需要搜寻。例如,可以在短短三个周期内访问小型现代 L1 缓存,而大型现代 L1 缓存可能需要五个周期的延迟。小型 L2 缓存可以低至 8 个周期,而大型 L2 缓存可能有 19 个周期。
缓存设计中涉及到的不仅仅是更大等于更慢,所有大型 CPU 设计公司都将煞费苦心地努力尽可能地缩短这些周期,因为通常 L1 缓存或 L2 缓存中的延迟节省提供良好的性能增益。但最终如果你做得更大,您必须满足这样一个事实,即延迟通常会更大,但您的缓存未命中率(cache miss )会更低。这又回到了上一段讨论定义的工作负载。我们看到像 AMD、英特尔、Arm 等公司与其大客户一起进行广泛的工作负载分析,以了解什么最有效以及他们的核心设计应该如何发展。
IBM 的革命在第一段中,我提到IBM Z是他们的大型主机产品——这是行业的大拿。它比政府授权的核掩体建造得更好。这些系统支撑着社会的关键要素,例如基础设施和银行业务。这些系统的停机时间以每年几毫秒为单位,并且它们具有故障安全和故障转移功能——对于金融交易,当它进行时,它必须无故障地提交给所有正确的数据库,甚至在发生故障的情况下整个链条的物理故障。
这就是IBM Z的用武之地。它非常小众,但具有令人难以置信的惊人设计。
在上一代z15产品中,没有1 CPU = 1系统产品的概念。IBM Z的基本单元是一个五处理器系统,使用两种不同类型的处理器。四个计算处理器 (CP) 每个在 696mm2中包含12个内核和256MB共享L3缓存,构建在14nm工艺上,运行频率为5.2GHz。这四个处理器分成两对,但两对也连接到存储控制器 (Storage Controller:SC),同样是 696mm和14nm,但是这个存储控制器拥有960MB的共享L4缓存,用于所有四个处理器之间的数据。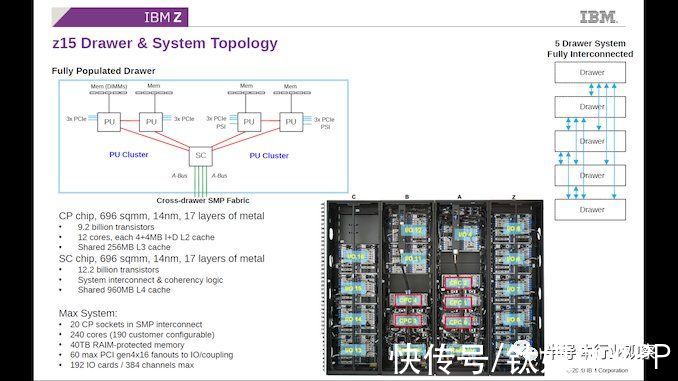
文章插图
请注意,该系统没有“全局”DRAM,每个计算处理器都有自己的 DDR 支持的等效内存。IBM 然后将这五个处理器“drawer”与其他四个处理器组合成一个系统。这意味着单个 IBM z15 系统是 25 x 696mm
的硅片面积,它们之间有 20 x 256 MB 的 L3 缓存,还有 5 x 960 MB 的 L4 缓存,以全对全拓扑连接。
可以说,IBM z15 是一头野兽。但是下一代 IBM Z,称为 IBM Telum 而不是 IBM z16,可能是因为他们对所有缓存采用了不同的方法。
IBM,告诉他们如何处理缓存新系统取消了带有 L4 缓存的单独存储控制器。相反,我们有一个看起来像八核的普通处理器。基于三星 7nm 和 530mm构建,IBM 将两个处理器封装在一起,然后将四个封装(8 个 CPU,64 核)集成到一个单元中。四个单元构成一个系统,总共 32 个 CPU/256 个内核。
文章插图
在单个芯片上,我们有八个内核。每个内核具有 32 MB 的私有 L2 缓存,具有 19 个周期的访问延迟。这对于 L2 缓存来说是一个很长的延迟,但它也比 Zen 3 的 L2 缓存大 64 倍,这是一个 12 周期的延迟。
文章插图
从芯片设计来看,中间的所有空间都是 L2 缓存。没有 L3 缓存。没有可供所有内核访问的物理共享 L3。如果没有 z15 那样的集中式缓存芯片,这意味着为了让具有一定数量共享数据的代码能够工作,它需要往返主内存,这很慢。但IBM已经想到了这一点。
- iphone13 pro|粉丝买美版iPhone13Pro,躲过了网络锁,却没想到有配置锁!
- 酷睿处理器|关键数据出炉,京东比阿里差远了
- 魅族|对不起!魅族,这次确实令人失望了
- 华为|问界M5风光无限,赛力斯SF5暗自神伤,华为或许低估了造车这事?
- 央视公开“支持”倪光南?柳传志该醒悟了
- 苹果|最具性价比的苹果手机来了,降价2120元,iPhone12已跌至冰点价
- 为了你的iPhone能磁吸充电,苹果又花了5亿买材料
- 5G|关于5G,华为赢了
- 造车|苹果造车一波三折,缺了一家“富士康”
- 百度|马化腾的一句话,腾讯市值一小时暴涨1400亿港币,马云格局还是小了