神经网络|UC伯克利发现「没有免费午餐定理」加强版:每个神经网络,都是一个高维向量( 三 )
其中,θ是一个参数向量。令训练样本为x,目标值为y,测试数据点为x',假设我们以较小的学习率η执行一步梯度下降,MSE 损失为。则参数会以如下所示的方式更新:
我们希望知道对于测试点而言,参数更新的变化有多大。为此,令θ线性变化,我们得到:
文章插图
其中,我们将神经正切核 K 定义为:
值得注意的是,随着网络宽度区域无穷大,修正项可以忽略不计,且在任意的随机初始化后,在训练的任何时刻都是相同的,这极大简化了对网络训练的分析。可以证明,在对任意数据集上利用 MSE 损失进行无限时长的训练后,网络学习到的函数可以归纳如下:
直观地说,核是一个相似函数,我们可以将它的高特征值特征函数解释为「相似」点到相似值的映射。在这里,我们的分析重点在于对泛化性的度量,我们将其称之为「可学习性」,它量化了标函数和预测函数的对齐程度:
我们将初始化的神经网络f和学习目标函数f^分别用特征向量展开: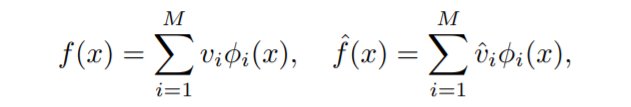
文章插图
这样就可以计算f和f^之间的接近(可学习)程度。
作者还推导出了学习到的函数的所有一阶和二阶统计量的表达式,包括恢复之前的 MSE 表达式。如图 3 所示,这些表达式不仅对于核回归是相当准确的,而且也可以精准预测有限宽度的网络。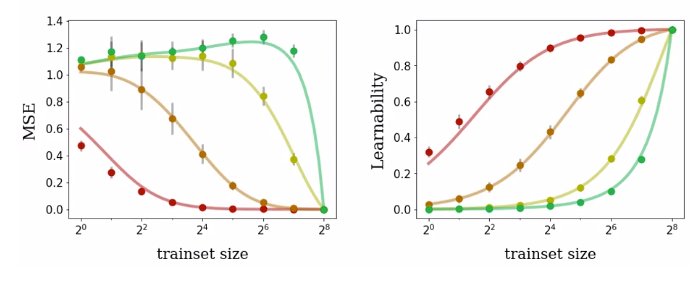
文章插图
图 3:为四种训练集大小不同的布尔函数训练神经网络的泛化性能度量。无论是对 MSE 还是可学习性而言,理论预测结果(曲线)与真实性能(点)都能够很好地匹配。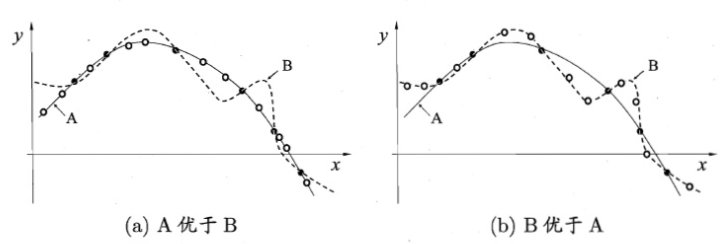
文章插图
图 4:经典的没有免费午餐定理(来源:《机器学习》,周志华)
简单地说,如果某种学习算法在某些方面比另一种学习算法更优,则肯定会在其它某些方面弱于另一种学习算法。具体而言,没有免费午餐定理表明:
- 1)对所有可能的的目标函数求平均,得到的所有学习算法的「非训练集误差」的期望值相同;
- 2)对任意固定的训练集,对所有的目标函数求平均,得到的所有学习算法的「非训练集误差」的期望值也相同;
- 3)对所有的先验知识求平均,得到的所有学习算法的「非训练集误差」的期望值也相同;
- 4)对任意固定的训练集,对所有的先验知识求平均,得到的所有学习算法的的「非训练集误差」的期望值也相同。
- 5G|华为利用5G毫米波发现园区入侵者,这让美国5G联盟情何以堪
- 发现最小白矮星,其大小相当于月亮,这让科学家很兴奋
- 玉兔二号发现的“神秘小屋”前不久|玉兔二号拍到的月球背面的房子到底是什么,终于揭晓了
- Google|在德国留学发现,华为手机在欧洲市场相当于一块砖头
- 一斗穷、二斗富?康熙10个“簸箕”,科学家发现斗与簸箕的奥秘
- 微信|发现微信好友朋友圈是“一条杠”,删还不不删?
- 青年报·青春上海记者 陈嘉音/文 郭容/图、视频手办和雕像作为收藏品|青年发现|为中国人塑像,国风潮流玩具的“破圈”故事
- 揭开神秘面纱?嫦娥四号获取新成果:在月球背面发现“天外来客”
- 审查|德国监管机构:未发现任何证据表明小米手机具有“审查”功能
- 83年前宣布灭绝的鱼被发现还活着1月9日|83年前宣布灭绝的鱼被发现还活着,看似普通的它,为何难以发现