神经网络|UC伯克利发现「没有免费午餐定理」加强版:每个神经网络,都是一个高维向量( 四 )
对于核回归问题而言,所有可能的目标函数的期望满足:
所有核特征函数的可学习性与训练集大小正相关。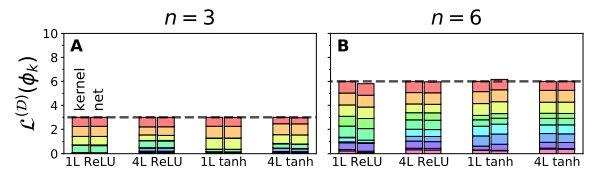
文章插图
图 5:可学习性的特征函数之和始终为训练集的大小。
如图 5 所示,堆叠起来的柱状图显式了一个在十点域上的十个特征函数的随机 D 可学习性。堆叠起来的数据柱显示了十个特征函数的 D-可学习性,他们都来自相同的训练集 D,其中数据点个数为 3,我们将它们按照特征值的降序从上到下排列。每一组数据柱都代表了一种不同的网络架构。对于每个网络架构而言,每个数据柱的高度都近似等于 n。在图(A)中,对于每种学习情况而言,左侧的 NTK 回归的 D-可学习性之和恰好为 n,而右侧代表有限宽度网络的柱与左侧也十分接近。
神经核的谱分析结果
文章插图
图 6:神经核的谱分析使我们可以准确地预测学习和泛化的关键度量指标。
图 6 中的图表展示了带有四个隐藏层、激活函数为 ReLU 的网络学习函数的泛化性能,其中训练数据点的个数为 n。理论预测结果与实验结果完美契合。
- (A-F)经过完整 batch 的梯度下降训练后,模型学到的数据插值图。随着 n 增大,模型学到的函数越来越接近真实函数。本文提出的理论正确地预测出:k=2 时学习的速率比 k=7 时更快,这是因为 k=2 时的特征值更大。
- (G,J)为目标函数和学习函数之间的 MSE,它是关于 n 的函数。图中的点代表均值,误差条代表对称的 1σ方差。曲线展示出了两盒的一致性,它们正确地预测了 k=2 时 MSE 下降地更快。
- (H,K)为伪本征模的傅里叶系数,。由于 k=2 时的特征值更大,此时的傅里叶系数小于 k=7 时的情况。在这两种模式下,当被充分学习时,傅里叶系数都会趋向于 0。实验结果表明理论预测的 1与实验数据完美契合。
- (I,L)可学习性:对于目标函数和学习到的函数对齐程度的度量。随着 n 增大,在[0,1]的区间内单调递增。由于 k=2 时的特征值更大,其可学习性也更高。

文章插图
图 7:理论预测值与任意特征函数在多种输入空间上的真实的可学习性紧密匹配。每张图展示了关于训练集大小 n 的特征函数的可学习性。NTK 回归和通过梯度下降训练的有限宽度网络的理论曲线完美匹配。误差条反映了1由于数据集的随机选择造成的方差。(A)单位圆上正弦特征函数的可学习性。作者将单位圆离散化为 M=2^8 个输入点,训练集包含所有的输入点,可以完美地预测所有的函数。(B)8d 超立方体顶点的子集对等函数的可学习性。k值较高的特征函数拥有较小的特征值,其学习速率较慢。当 n =2^8 时,所有函数的预测结果都很完美。虚线表示 L-n/m 时的情况,所有函数的可学习性都与一个随机模型相关。(C)超球谐函数的可学习性。具有较高 k 的特征函数有较小的特征值,学习速率较慢,在连续的输入空间中,可学习性没有严格达到 1。
- 5G|华为利用5G毫米波发现园区入侵者,这让美国5G联盟情何以堪
- 发现最小白矮星,其大小相当于月亮,这让科学家很兴奋
- 玉兔二号发现的“神秘小屋”前不久|玉兔二号拍到的月球背面的房子到底是什么,终于揭晓了
- Google|在德国留学发现,华为手机在欧洲市场相当于一块砖头
- 一斗穷、二斗富?康熙10个“簸箕”,科学家发现斗与簸箕的奥秘
- 微信|发现微信好友朋友圈是“一条杠”,删还不不删?
- 青年报·青春上海记者 陈嘉音/文 郭容/图、视频手办和雕像作为收藏品|青年发现|为中国人塑像,国风潮流玩具的“破圈”故事
- 揭开神秘面纱?嫦娥四号获取新成果:在月球背面发现“天外来客”
- 审查|德国监管机构:未发现任何证据表明小米手机具有“审查”功能
- 83年前宣布灭绝的鱼被发现还活着1月9日|83年前宣布灭绝的鱼被发现还活着,看似普通的它,为何难以发现