功耗|既快又准并且低开销!一作亲解MICRO 2021最佳论文:一种自动化功耗模拟架构( 四 )
在选取的过程中,会加一个非常强的penalty strength,使99.9%的weight全都变成0,这样可以使选取的信号最具有代表性。对penalty加的是一个叫做Minimax concave penalty(MCP),用于剪枝算法。
选取有代表性的信号,基于这些信号,重新训练一个线性的模型,这个线性的模型就是最终的模型。这是第一步,也是最重要的一步。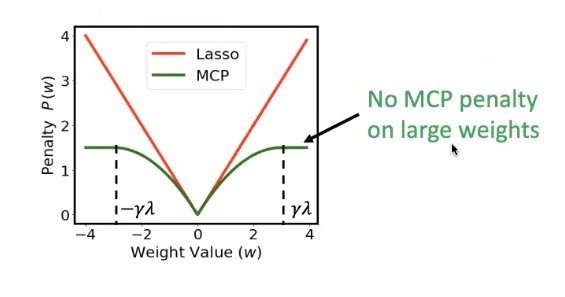
文章插图
另外我们观察到MCP选择的信号,彼此之间的相关性更小,这说明我们选的信号是有代表性的。
开始有一些随机 workload,由于是随机生成的,因此它的功耗比较低。我们选取里面功耗高的做crossover或mutate,这就是遗传算法基本操纵。然后生成一些更高功耗的workload,一代又一代功耗会不断增加。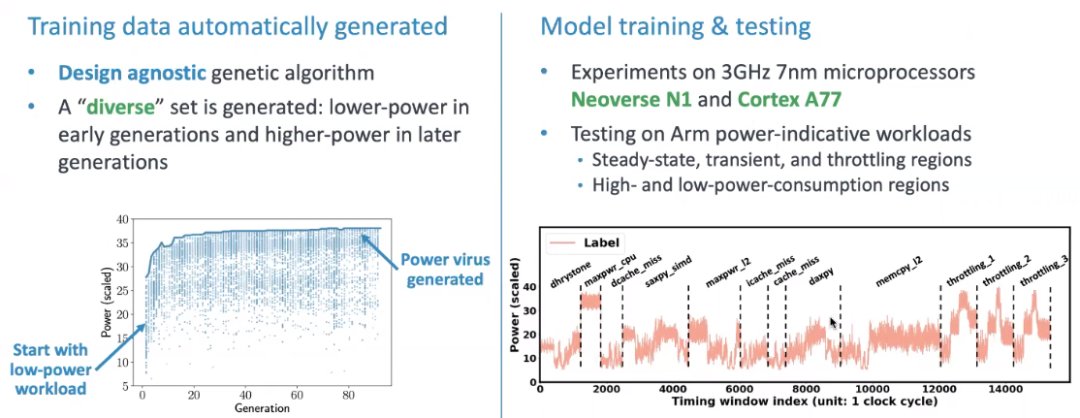
文章插图
测试的时候也需要workload,这些workload是工程师手动写出来的,非常具有代表性。我们选选择了12个,既有有低功耗也有高功耗,还有快速变化的和保持不变的,覆盖了各种类型。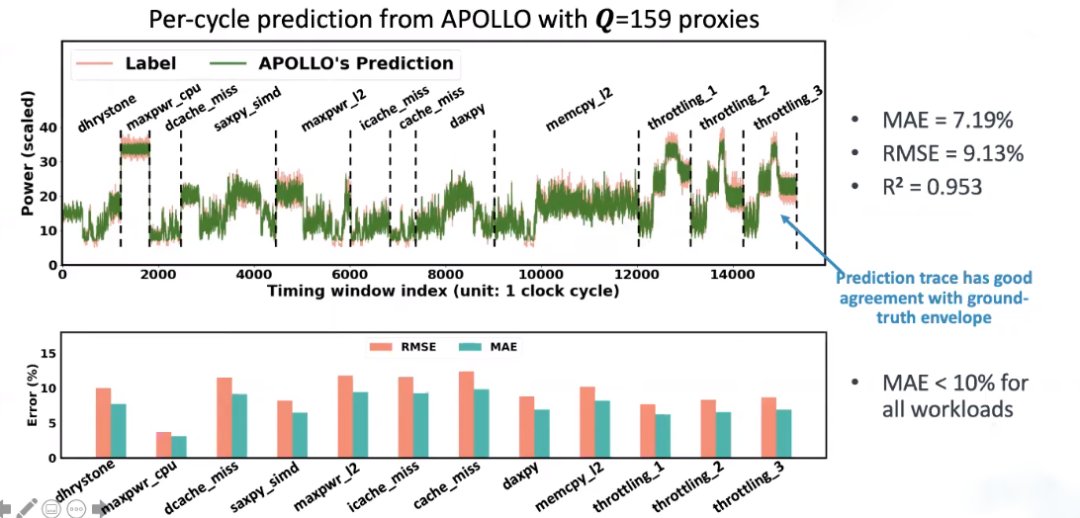
文章插图
同时我们计算了每个workload的MAE,发现所有类型的workload的MAE都少于10%,这说明了它的准确性。并且即使是7%的错误,也是由于清晰度太高,导致每个cycle之间有一个小错误这个是很难避免的。如果从一个更大的measurement window来算平均power,就会更准确。
事实上,APOLLO可以对任何一个measurement window进行计算,而不仅仅是 per-cycle。
- 小米12|自研动态性能调度!小姐姐实测小米12 Pro《王者荣耀》:功耗下降20%
- 智商税|明年的12代非K处理器值不值得冲?性能功耗到底如何?
- CPU|超能课堂:为200W功耗的CPU进行散热,需要多大风量的风扇?
- 酷冷至尊|炫彩屏幕可显示功耗/转速!酷冷至尊XG PLUS 850W白金牌电源图赏
- 尼康|65W闪充+6400万像素,优质旗舰价格跌至2099,性能功耗体验是亮点
- 高通骁龙|骁龙888对比骁龙865,功耗是其最大槽点
- 联想|联想拯救者Y9000P 2022笔记本预热:最高可选RTX 3070Ti、150W满功耗释放
- AMD|超低功耗速龙金牌PRO 4150GE稳了!Zen2架构、GPU飞升
- m荣耀MagicUI 6.0发布:AI全场景智慧进化 功耗直降95%
- 智能手机|荣耀MagicUI 6.0发布:AI全场景智慧进化 功耗直降95%