功耗|既快又准并且低开销!一作亲解MICRO 2021最佳论文:一种自动化功耗模拟架构( 五 )
文章插图
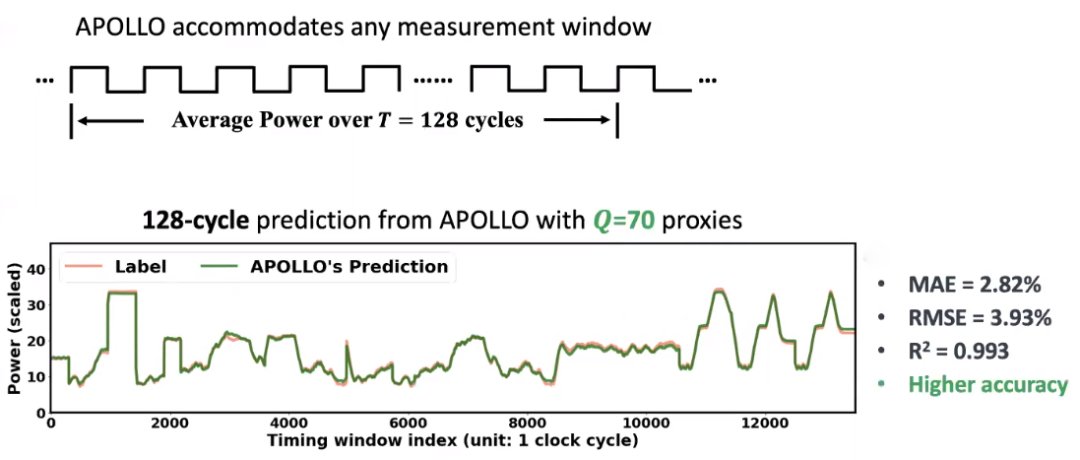
如上图,如果现在不需要per-cycle,只要一个average power ,over128个cycle,在这种情况下,只需要70个input,就可以做出一个准确的预测。预测结果error小于3%,如果能够容忍一个更大的measurement window,准确度将会几乎接近100%,因此在降低条件的情况下,它的性能可以有进一步的提升。
首先有Q个输入作为input,输入全都是0或者1,因此这个模型里面不需要乘法器,这样可以节省很大一笔开销。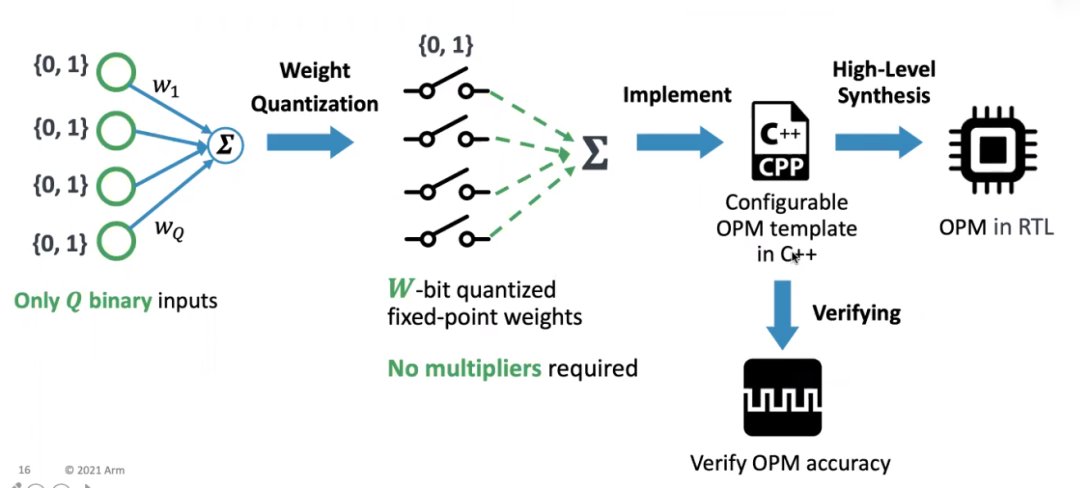
文章插图
同时weight作为quantization,不需要64位的weight那么准,只要需要十几位的weight,就可以很准确,因此开销又变得小了。
基于这个模型,用c++就可以很简单实现这个OMP模型,然后基于 C++的template,进行Hign-Level Synthesis,获得 design的RTL,如果这个RTL 可以和CPU的RTL合在一起,然后我们去做 tape out,这是一个最基本的思路,而流程本身也很简单。
同时基于C++的硬件设计,还可以verifying,可以验证硬件设计也是准确的。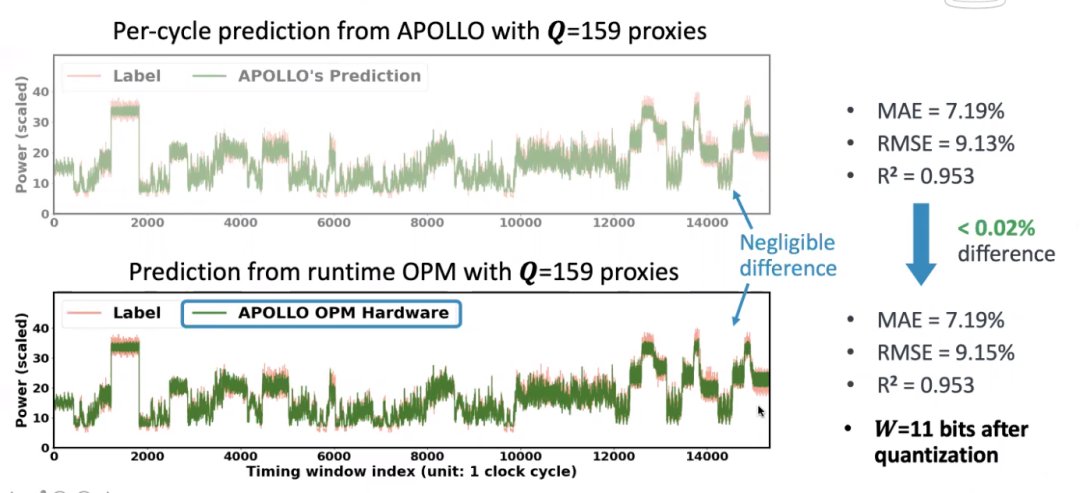
文章插图
硬件一定有trade off,在accuracy和hardware cost之间寻求一个平衡,因此我们计算了一下它到底是如何trade off的,然后来辅助我们设计一个这样的模块。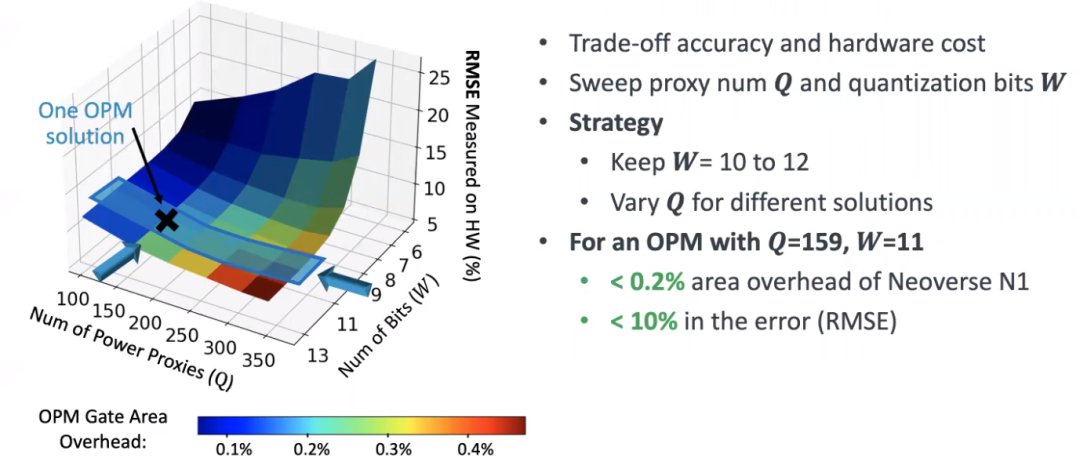
文章插图
如图所示,我们用y轴来表示它的accuracy in error,然后用这个颜色来表示它在硬件上的代价(area overhead),即占CPU比例是多少。
首先可以改变input的数量,另外一方面可以改变 quantization bits,我们改变这两个值观察它对accuracy和area overhead的trade off。
如上图,测量的结果中每个点都会有一个accuracy对应的hardware cost。当W继续小于10时,area会飞快的上升,即quantization 加的太大了,已经使原来的X扭曲掉了。所以quantization不能加的过大,并且W没必要大于12。因此我们策略是保持 W在10~12之间。
如果需要不同的solution,可以改变Q。比如我们根据这个策略,我们现在选到1个solution。如上图,OPM的Q是159,weight是11位,error大概是10%,在Neoverse N1上它的area overhead小于0.2%。所以我们认为它的实现代价非常低,并且准确率足够高,因此我们认为这是一个非常不错的 solution。
所以到现在我已经介绍了它在设计时期,作为一个软件的准确率,和它在片上作为一个硬件的准确率以及实现的代价。
文章插图
为了进一步利用这个性质,我们可以允许CPU的设计师或架构师,自己限制来源范围,从里面找最有代表性的信号等,可以使设计师更容易理解这些信号。通过这种方法,这个模型的可解释性就变得更强,然后更能够辅助设计师来进行设计的决策。这当然这个是有一定代价的,如果限制了输入,它的准确率会有一定的下降,但下降非常少。
- 小米12|自研动态性能调度!小姐姐实测小米12 Pro《王者荣耀》:功耗下降20%
- 智商税|明年的12代非K处理器值不值得冲?性能功耗到底如何?
- CPU|超能课堂:为200W功耗的CPU进行散热,需要多大风量的风扇?
- 酷冷至尊|炫彩屏幕可显示功耗/转速!酷冷至尊XG PLUS 850W白金牌电源图赏
- 尼康|65W闪充+6400万像素,优质旗舰价格跌至2099,性能功耗体验是亮点
- 高通骁龙|骁龙888对比骁龙865,功耗是其最大槽点
- 联想|联想拯救者Y9000P 2022笔记本预热:最高可选RTX 3070Ti、150W满功耗释放
- AMD|超低功耗速龙金牌PRO 4150GE稳了!Zen2架构、GPU飞升
- m荣耀MagicUI 6.0发布:AI全场景智慧进化 功耗直降95%
- 智能手机|荣耀MagicUI 6.0发布:AI全场景智慧进化 功耗直降95%