晓查 丰色 发自 凹非寺
量子位 报道 | 公众号 QbitAI
NeurIPS 2021将于下周正式召开。
今天,大会委员会公布了NeurIPS 2021的杰出论文奖,时间测试奖,以及今年新设的数据集和测试基准最佳论文奖。
杰出论文奖今年有六篇论文被选为杰出论文奖的获得者。委员会之所以选择这些论文,是因为它们具有出色的清晰度、洞察力、创造力和持久影响的潜力。
A Universal Law of Robustness via Isoperimetry论文地址:
https://openreview.net/pdf?id=z71OSKqTFh7

文章插图
这篇论文来自微软以及斯坦福大学,关键字为对抗鲁棒性、过参数化和isoperimetry(等周图形学)。
获奖理由:
本文提出了一个理论模型,来解释为什么许多SOTA深度网络模型需要比平滑拟合训练数据还需多得多的参数。
特别地,在训练分布的某些规律性条件下,O(1)-Lipschitz函数在标签噪声scale之下插入训练数据所需的参数数量为nd,其中n是训练示例的数量,d是数据的维度。
这一结果与传统结果形成鲜明对比。传统结果表明一个函数需要n个参数来插入训练数据,而现在则发现,参数d似乎是保证数据平滑插入所必需的。
该理论简单而优雅,和对MNIST分类具有鲁棒泛化能力的模型规模的观察结果也一致。
这项工作还为ImageNet分类开发稳健模型所需的模型大小提供了可测试的预测。
On the Expressivity of Markov Reward论文地址:
https://openreview.net/forum?id=9DlCh34E1bN
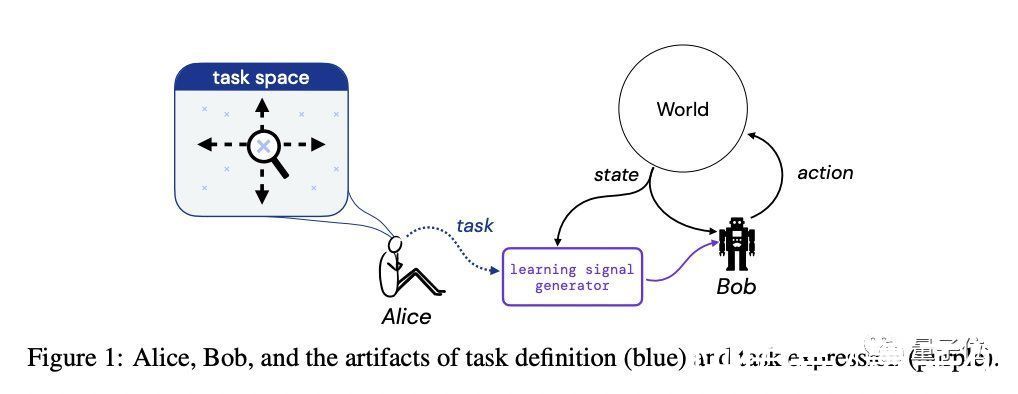
文章插图
这篇论文来自DeepMind、普林斯顿大学和布朗大学,研究方向为强化学习,通过检查马尔可夫奖励函数可以表达什么样的任务来研究有限环境中马尔可夫奖励函数的表达能力。
获奖理由:
马尔可夫奖励函数是不确定性和强化学习下顺序决策的主要框架。
本文详细、清晰地阐述了马尔可夫奖励何时足以或不足以使系统设计者根据其对行为、特定行为的偏好,或对状态和动作序列的偏好来指定任务。
作者通过简单的说明性示例证明,存在一些无法指定马尔可夫奖励函数来引发所需任务和结果的任务。
幸运的是,他们还表明,可以在多项式时间内确定所需设置是否存在兼容的马尔可夫奖励,如果存在,也存在多项式时间算法来在有限决策过程设置中构建这样的马尔可夫奖励。
这项工作阐明了奖励设计的挑战,并可能开辟未来研究马尔可夫框架何时以及如何足以实现人类所需性能的途径。
Deep Reinforcement Learning at the Edge of the Statistical Precipice论文地址:
https://openreview.net/forum?id=uqv8-U4lKBe
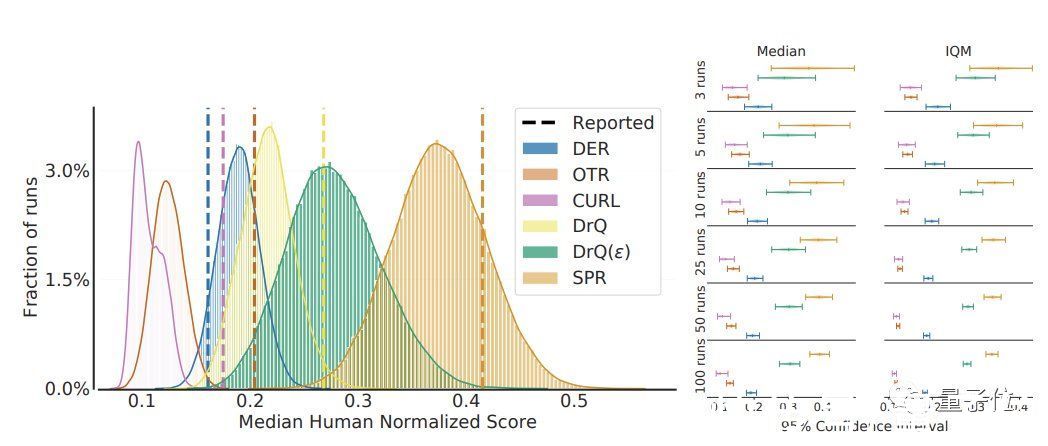
文章插图
论文来自谷歌、蒙特利尔大学和麦吉尔大学,研究方向也是强化学习。
获奖理由:
方法的严格比较可以加速有意义的科学进步。本文提出了提高深度强化学习算法比较严谨性的实用方法。
具体而言,新算法的评估应提供分层的引导程序置信区间、跨任务和运行的性能概况以及四分位数均值。
该论文强调,在许多任务和多次运行中报告深度强化学习结果的标准方法,可能使评估新算法和过去方法之间的一致性和提升变得困难,并通过实证示例说明了这一点。
所提出的性能比较方法旨在通过每个任务的少量运行进行计算,这对于许多计算资源有限的研究实验室来说可能是必要的。
MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers论文地址:
- text|《2021大数据产业年度创新技术突破》榜重磅发布丨金猿奖
- 酷睿处理器|关键数据出炉,京东比阿里差远了
- OpenHarmony 项目群 12 月新增捐赠人美的集团、深圳开鸿
- 财智干货|数智化发展任重道远,财务中台提升数据服务价值 | 大数据
- 支付宝集五福活动 1 月 19 日正式开始,现可提前领福
- 美少女1985集
- 央媒表态后,联想关键数据出炉,柳传志这回要扳回一局?
- 电子封装技术、微电子、集成电路等,电子信息类专业,研究方向
- 数据库|OPPO悄悄上新机,骁龙8核+5000mAh电池,256G仅售1599元
- 注册资本|美的集团投资成立汽车部件公司,注册资本 2 亿元