https://openreview.net/forum?id=Tqx7nJp7PR
文章插图
论文作者来自华盛顿大学、艾伦研究所和斯坦福大学。
获奖理由:
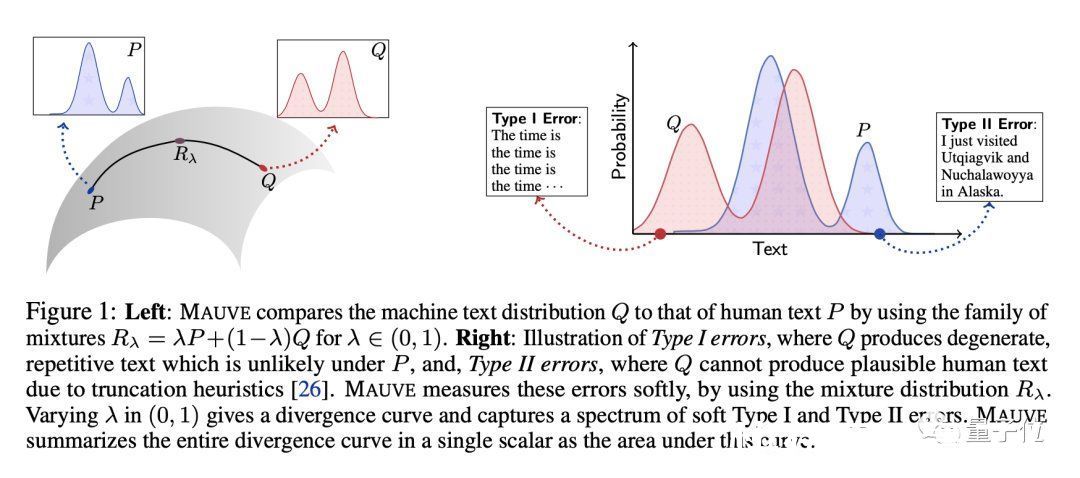
本文介绍了 MAUVE,这是一种比较模型生成文本分布与人类生成文本分布的散度度量。这个想法简单而优雅,它基本上使用了被比较的两个文本的量化嵌入的(soft)KL 散度测量的连续族。
本出提议的MAUVE度量本质上是对连续度量系列的集成,目标是捕获I类错误(生成不切实际的文本)和II类错误(不捕获所有可能的人类文本)。
实验表明,与之前的散度指标相比,MAUVE可以识别模型生成文本的已知模式,并且与人类判断的相关性更好。
这篇论文写得很好,研究问题在开放式文本生成快速发展的背景下很重要,而且结果很明确。
Continuized Accelerations of Deterministic and Stochastic Gradient Descents, and of Gossip Algorithms论文地址:
https://openreview.net/forum?id=bGfDnD7xo-v
本篇论文来自巴黎文理研究大学、洛桑联邦理工学院、格勒诺布尔-阿尔卑斯大学、MSR-Inria联合中心。
获奖理由:
本文描述了Nesterov加速梯度方法的“连续化”版本,其中两个独立的向量变量在连续时间内共同演化——很像以前使用微分方程来理解加速度的方法——但使用梯度更新,随机时间发生在泊松点过程。
这种新方法导致了一种(随机化)离散时间方法:
(1)与Nesterov方法具有相同的加速收敛性;
(2) 带有利用连续时间参数的清晰透明的分析,这可以说比之前对加速梯度方法的分析更容易理解;
(3) 避免了连续时间过程离散化的额外错误,这与之前使用连续时间过程理解加速方法的几次尝试形成鲜明对比。
Moser Flow:Divergence-based Generative Modeling on Manifolds论文地址:
https://openreview.net/forum?id=qGvMv3undNJ
文章插图
本文作者来自魏茨曼科学研究学院、Facebook和加州大学洛杉矶分校。
获奖理由:
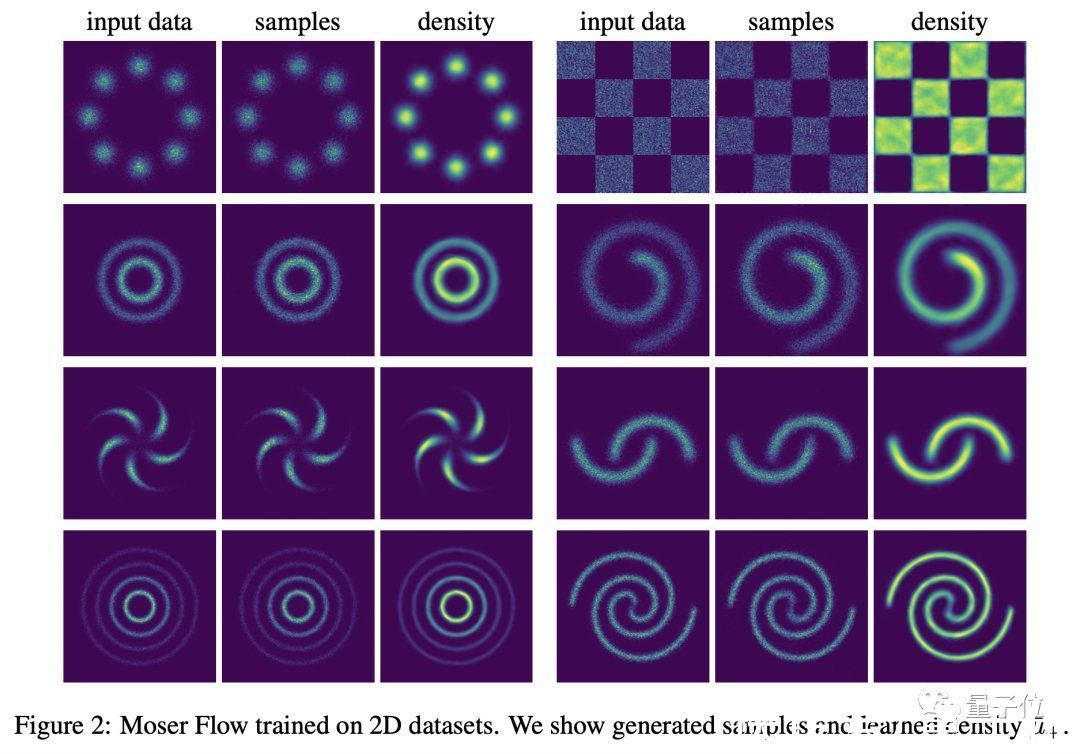
【 数据集|NeurIPS 2021杰出论文等奖项公布,斯坦福大学3篇入选,成最大赢家】本文提出了一种在黎曼流形上训练连续归一化流 (CNF) 生成模型的方法。关键思想是利用 Moser (1965) 的结果,该结果使用具有几何规律性条件的受限常微分方程(ODE)类来表征 CNF的解,并使用散度明确定义目标密度函数。
本文提出的Moser Flow方法使用此解决方案概念,来开发基于参数化目标密度估计器的CNF方法。训练相当于简单地优化密度估计器的散度,回避运行标准反向传播训练所需的ODE求解器。
实验表明,与之前的CNF工作相比,它的训练时间更快,测试性能更出色,并且能够对具有非常数曲率的隐式曲面的密度进行建模。
时间检验奖从去年开始,NeurIPS时间检验奖(Test of Time Award)选择了更广的年限范围。因此,今年大会委员会选择2010年2011年论文。
在16篇引用量超过500的论文里,委员会选择了这篇论文:
Online Learning for Latent Dirichlet Allocation

文章插图
论文地址:
https://proceedings.neurips.cc/paper/2010/file/71f6278d140af599e06ad9bf1ba03cb0-Paper.pdf
作者来自普林斯顿大学和法国国家信息与自动化研究所。
第一作者Matthew D. Hoffman发表这篇论文时,曾经在普林斯顿攻读博士学位,现在他是谷歌一名高级研究科学家。
本文介绍了一种基于随机变分梯度的推理过程,用于在非常大的文本语料库上训练潜在狄利克雷分配 (LDA) 模型。在理论方面,它表明训练过程收敛到局部最优,令人惊讶的是,简单的随机梯度更新对应于ELBO目标的随机自然梯度。
- text|《2021大数据产业年度创新技术突破》榜重磅发布丨金猿奖
- 酷睿处理器|关键数据出炉,京东比阿里差远了
- OpenHarmony 项目群 12 月新增捐赠人美的集团、深圳开鸿
- 财智干货|数智化发展任重道远,财务中台提升数据服务价值 | 大数据
- 支付宝集五福活动 1 月 19 日正式开始,现可提前领福
- 美少女1985集
- 央媒表态后,联想关键数据出炉,柳传志这回要扳回一局?
- 电子封装技术、微电子、集成电路等,电子信息类专业,研究方向
- 数据库|OPPO悄悄上新机,骁龙8核+5000mAh电池,256G仅售1599元
- 注册资本|美的集团投资成立汽车部件公司,注册资本 2 亿元