
文章图片
文章图片

文章图片

文章图片

训练计算机视觉模型是复杂而反复的工作的一个组成部分 , 通常看起来会复杂的令人生畏 。 但是其实了解了模型和基础算法 , 一切都会变得简单了
下面 , 我将着重于有监督的学习 , 该学习使用标记的训练数据来指导模型期望的输出是什么 。 介绍模型训练过程的每个组成部分 , 并将作为大家深入了解计算机视觉的基础 。
型号类型不同的计算机视觉模型可以帮助我们回答有关图像的问题 。
图像中有哪些物体?
图像中的那些对象在哪里?
对象上的关键点在哪里?
每个对象属于哪些像素?
我们可以通过构建不同类型的DNN来回答这些问题 。 然后 , 可以将这些DNN用于应用程序中 , 以解决诸如确定图像中有多少辆汽车 , 一个人是坐着还是站着 , 或者图片中的动物是猫还是狗的问题 。 我们在下面概述了几种最常见的计算机视觉模型及其用例 。
通常 , 计算机视觉模型输出由标签和置信度或得分组成 , 这是对正确标记对象的可能性的一些估计 。 这个定义是故意含糊的 , 因为对于不同类型的模型 , “信心”将意味着截然不同的事物 。
在描述不同类型的模型及其用例时 , 我们将概述一个虚拟衣橱的用例
示例:一个应用程序 , 使用户可以在购买之前虚拟地试穿不同的服装 。
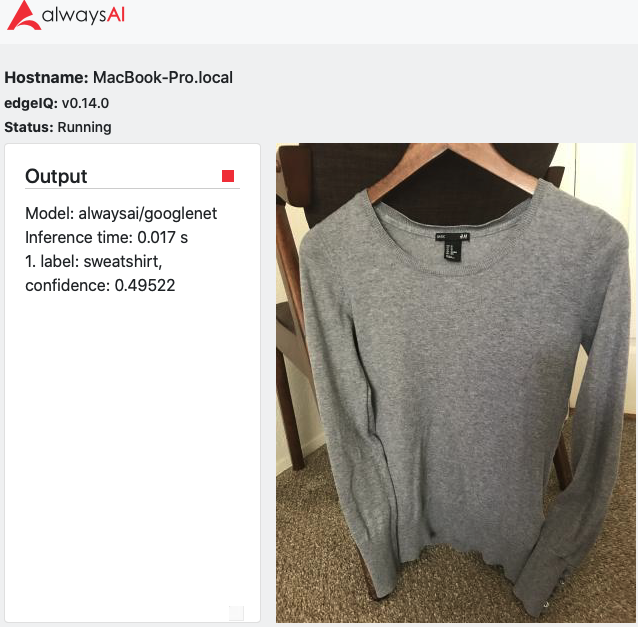
影像分类图像分类尝试识别图像中最重要的对象类别 。 在计算机视觉中 , 我们将每个类称为标签 。 例如 , 我们可以使用通用的分类模型(例如“ alwaysai / googlenet ”)来识别衣物 , 例如“跑步鞋”或“运动衫” , 如下所示 。 该模型将以图像作为输入 , 并且将输出一个标签以及模型对特定标签的信心(与其他标签相比) 。 此外 , 用于图像分类任务的DNN不提供图像中对象的位置 , 因此对于需要此信息的用例 , 例如为了跟踪或计数对象 , 我们需要使用对象检测模型 , 以及接下来的模型描述 。
物体检测当对象的位置很重要时 , 通常使用对象检测 DNN 。 这些网络返回一组坐标 , 称为边界框 , 它指定输入图像中包含对象的区域 , 以及该边界框和标签的置信度值 。 对于我们的“虚拟衣橱”应用程序 , 我们需要一个想要试穿虚拟衣服的人的输入图像 , 然后我们需要在图像中找到该人 。 为此 , 我们可以使用对象检测模型进行人员检测 , 例如' alwaysai / mobilenet_ssd” , 那么它将返回一个围绕图像中每个人的边界框 , 以及标签“人”和输出的置信度值 。 下面显示了可以区分人的对象检测模型的示例 。
注意:知道对象在框架中的位置可以使我们推断出有关图像的某些信息 。 例如 , 我们可以计算出高速公路上有多少辆汽车来规划交通模式 。 我们还可以通过将分类模型附加到对象检测模型上来扩展应用程序的功能 。 例如 , 我们可以将图像中与边界框相对应的部分从检测模型中输入到分类模型中 , 以便我们可以计算图像中相对于轿车的卡车数量 。
注:图片小姐姐就是作者本人
- 计算机视觉|2019年AI计算机视觉将继续承担哪些作用?
- 鼠标|C4D图标视觉UI设计!质感满满
- 高发|C4D图标视觉UI设计!质感满满
- 计算机的三类总线分别是控制总线、地址总线和数据总线|计算机的三类总线是什么?
- onedrive是win8、win10等系统自带的软件|onedrive卸载后会影响计算机系统的安全性
- ARM|ARM前途迷茫!转身后的阿里果断下注,谷歌也开始出击
- 张艺谋电影上天了!《满江红》主视觉随运载火箭发射升空
- 谷歌发布全新反向推理算法LAMBADA|谷歌最新自然语言推理算法
- 涨停|聚焦|苹果隐私政策影响电商行业、谷歌和Meta市场份额创新低...
- 芯片|被中国芯片企业牵着走?谷歌官宣了,美媒:美芯的“天”变了